Cekura
Cekura는 음성·채팅 AI 에이전트의 엔드투엔드 테스트와 관측을 제공하며, 사전 시뮬레이션과 운영 모니터링으로 대화 품질을 점검합니다.
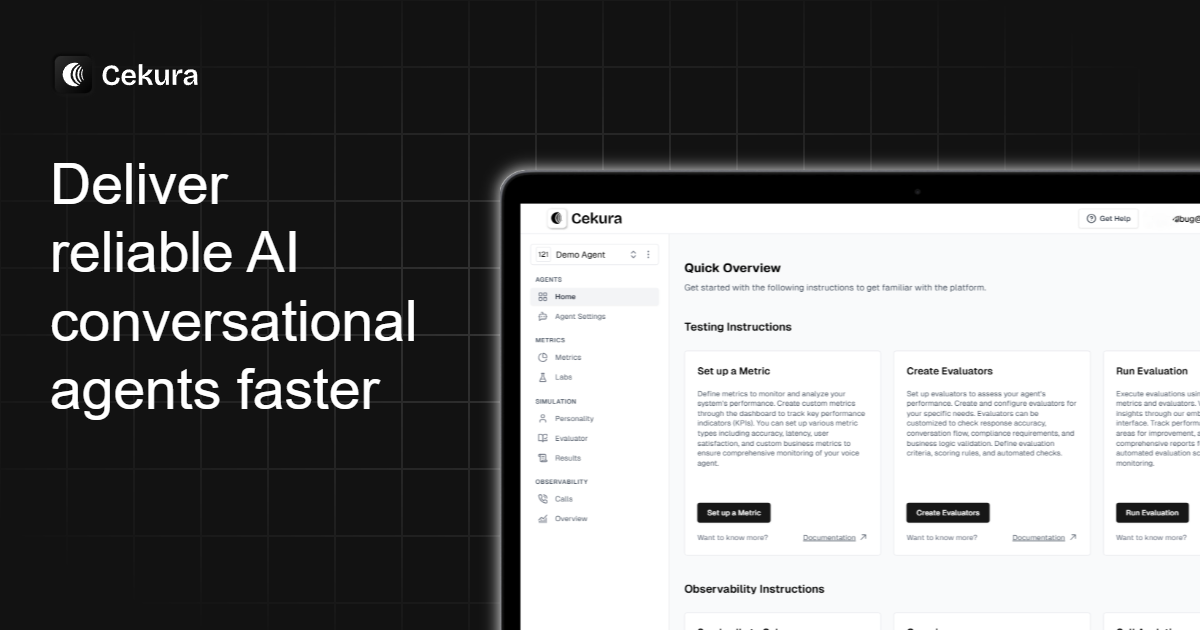
Cekura란 무엇인가요?
Cekura는 음성 및 채팅 시스템을 포함한 대화형 AI 에이전트를 위한 엔드투엔드 테스트 및 관측 도구입니다. 핵심 목적은 출시 전에 다양한 대화 시나리오에서 에이전트의 동작을 검증하고, 운영 중 실제 대화를 모니터링하여 팀을 지원하는 것입니다.
플랫폼은 사전 제작 시뮬레이션(지시 따르기, 도구 호출, 대화 품질 테스트)과 운영 모니터링(통화 검사 및 누락된 체크나 예상 흐름 실패 등의 문제 식별)을 지원합니다.
주요 기능
- 음성 및 채팅 에이전트를 위한 시나리오 시뮬레이션: 다양한 사용자 및 대화 조건에서 에이전트 동작을 검증하기 위해 대규모 시나리오 세트로 사전 제작 테스트 실행.
- 페르소나 및 성격 기반 테스트: 미리 정의된 페르소나(예: 다양한 억양, 성별, 사용자 성향)를 사용해 다양한 대화 스타일에서 에이전트의 적절한 응답 여부 평가.
- 병렬 호출 및 실행 가능한 평가: 핵심 사용자 흐름과 관련된 문제를 드러내기 위해 시뮬레이션 실행 및 평가 결과 몇 분 만에 생성.
- 알려진 문제 대화 재생: 프롬프트나 에이전트 로직 변경 시 반복 실패를 방지하기 위해 이전 문제 대화 패턴 재실행.
- 실시간 인사이트 및 로그를 통한 관측성: 상세 로그와 추세 분석으로 운영 대화 모니터링하며 지시 따르기, 도구 호출, 전체 대화 품질 평가.
- 오류 및 성능 저하 알림: 실패나 성능 저하 발생 시 즉시 알림 전송으로 팀의 빠른 대응 지원.
Cekura 사용 방법
- 에이전트 워크플로에 맞는 시나리오 생성 또는 선택으로 시작(표준 흐름 및 엣지 케이스 포함). Cekura는 수천 개의 내장 시나리오 라이브러리를 사용하거나 사용자 지정 시나리오를 만들 수 있습니다.
- 페르소나를 사용해 혼란스러운 사용자, 끼어드는 사용자, 스크립트 이탈 사용자 등 다양한 사용자 유형에서 에이전트 성능을 테스트하는 사전 제작 시뮬레이션 실행.
- 취소, 재예약, 후속 조치 등 핵심 작업에 영향을 미치는 문제에 대한 평가 결과 검토하고, 프롬프트나 동작 변경 후 알려진 문제 지점 재테스트를 위해 리플레이 사용.
- 운영 모니터링 배포로 실제 대화 관찰, 로그 검사, 알림을 통해 실패, 누락된 체크, 성능 저하 포착.
사용 사례
- 약속 흐름 프롬프트 변경 회귀 테스트: “새 프롬프트가 약속 취소를 망쳤다”면 시뮬레이션으로 변경이 취소, 재예약, 관련 후속 작업에 미치는 영향 확인.
- 중단 및 스크립트 이탈 사용자 처리: 에이전트가 조급하거나 끼어드는 동작에 대처하면서 의도된 지침을 따르는지 평가.
- 규정 준수 체크 및 면책 조항 검증: 필수 면책 조항이나 체크가 건너뛰어지지 않도록 핵심 흐름 테스트.
- 반복 대화 실패 문제 해결: “항상 문제를 일으키는 오래된 대화”를 리플레이해 실패 원인 파악 및 업데이트 후 수정 확인.
- 지시 따르기 및 도구 호출 운영 모니터링: 모든 통화에서 에이전트가 지시를 올바르게 따르고 예상 도구 호출을 수행하는지 확인하며 시간 경과 추적.
자주 묻는 질문
-
Cekura는 사전 제작만 테스트하나요, 운영도 모니터링하나요? Cekura는 둘 다 지원합니다: 평가를 위한 사전 제작 시뮬레이션과 지속 관측을 위한 운영 모니터링.
-
Cekura가 수행하는 평가 유형은 무엇인가요? 사이트는 지시 따르기, 도구 호출, 대화 품질 평가를 설명하며, 공감/반응성 점수와 건너뛴 규정 준수 체크 포착 등의 예시 체크를 포함합니다.
-
다양한 사용자 유형과 대화 스타일을 테스트할 수 있나요? 네. Cekura는 페르소나 기반 테스트(예: 다양한 억양 및 사용자 성향)를 포함하며 사용자 지정 시나리오를 지원합니다.
-
프롬프트나 에이전트 동작을 변경할 때 Cekura가 어떻게 도와주나요? 핵심 사용자 흐름의 빠른 재시뮬레이션과 알려진 문제 대화 리플레이를 통해 프롬프트 변경이 결과에 미치는 영향 평가 가능.
-
문제가 팀에 어떻게 전달되나요? 플랫폼은 오류, 실패, 성능 저하에 대한 즉시 알림/경고를 포함하며, 로그와 추세 분석을 제공합니다.
대안
- 독립형 LLM/에이전트 테스트 프레임워크: 테스트 케이스 실행과 평가에 초점을 맞춘 도구(종종 전체 대화 관측성 없음). 모니터링을 별도로 처리 중이라면 더 적합할 수 있습니다.
- 대화 분석 및 모니터링 플랫폼: 운영 대화 분석(대시보드, 로그, 트렌드)에 초점을 맞춘 솔루션. 구조화된 사전 운영 페르소나 시뮬레이션 워크플로를 제공하지 않을 수 있습니다.
- 고객 지원 QA 및 티켓 분석 도구: 지원 상호작용을 사후 분석하는 시스템. 검토와 보고에 도움이 되지만 지시 따르기와 도구 호출에 대한 엔드투엔드 시뮬레이션을 제공하지 않을 수 있습니다.
- 커스텀 스크립트 기반 에이전트 워크플로 테스트: 시나리오 실행과 점수를 위한 자체 하네스 구축. 유연하지만 페르소나 시뮬레이션, 재생, 알림 워크플로에 도달하려면 일반적으로 더 많은 엔지니어링 노력이 필요합니다.
대안
BenchSpan
BenchSpan은 AI 에이전트 벤치마크를 병렬 실행하고 점수·실패를 실행 이력으로 정리하며, 커밋 태그로 재현 가능한 결과 비교를 돕습니다.
PromptScout
PromptScout은 ChatGPT, Gemini, Google AI Overviews, Perplexity의 AI 답변에서 브랜드 언급·경쟁사 추천·인용 출처를 추적하며 웹사이트 감사와 함께 제공합니다.
Sleek Analytics
Sleek Analytics로 실시간 방문자 추적을 간편하게 확인하세요. 유입 출처, 본 페이지, 머문 시간까지 프라이버시 친화적으로 제공합니다.
Codex Plugins
Codex Plugins로 스킬, 앱 통합, MCP 서버를 재사용 워크플로로 묶어 Gmail·Google Drive·Slack 같은 도구 접근을 확장하세요.
MacSpoof
MacSpoof로 macOS Wi‑Fi MAC 주소를 변경하거나 랜덤화하세요. 네트워크 재접속 및 공용 Wi‑Fi에서 기기 식별 기록을 줄이는 데 도움.
ClawTick
ClawTick은 크론 스케줄로 웹훅 태스크를 실행하는 CLI-first AI 에이전트 자동화 플랫폼입니다. 모니터링·알림·재시도·실행 로그 제공