SemanticGuard
SemanticGuard는 OpenAI, Anthropic, Google의 LLM API를 위한 AI 게이트웨이로, 자체 검증 캐시로 비용 절감과 의미상 유사한 응답 캐싱, 캐시 장애 시에도 요청 유지를 지원합니다.
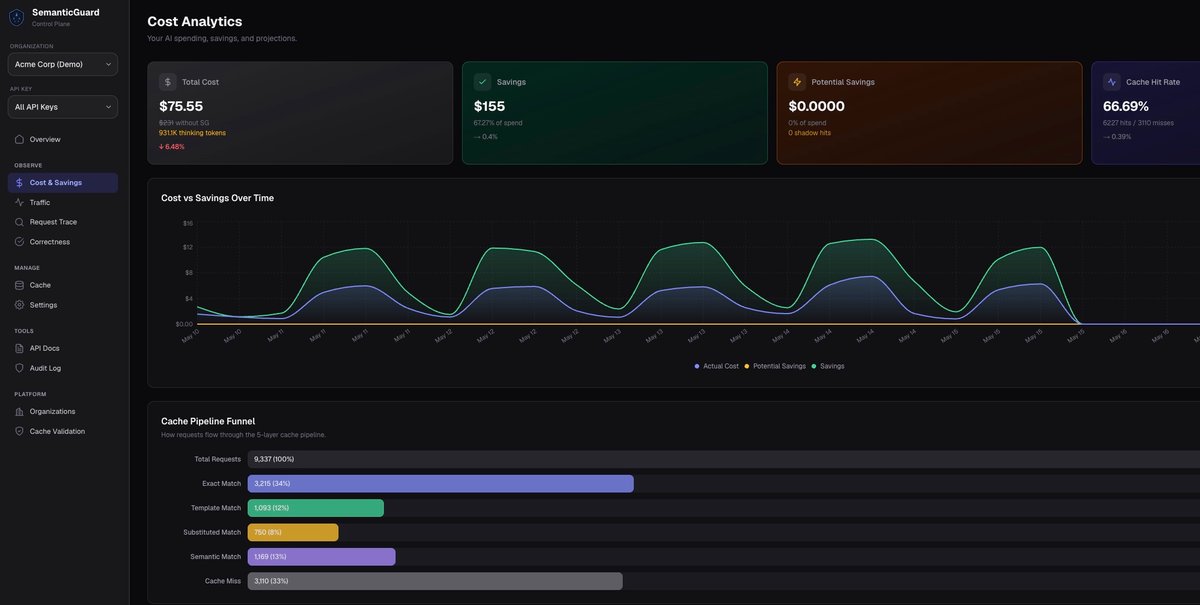
SemanticGuard란?
SemanticGuard는 LLM API를 위한 AI 게이트웨이이자 자체 검증 캐시입니다. OpenAI, Anthropic, Google 같은 공급자의 요청 경로에 위치해 응답을 캐싱하면서, 다층 검증으로 캐시된 답변이 아직 올바른지 확인합니다.
이 제품은 사용자가 프롬프트를 바꾸거나 캐시 객체를 수동으로 관리하지 않아도 LLM API 비용을 줄이도록 설계되었습니다. 또한 캐싱을 켜기 전에 잠재 절감액을 측정하는 Shadow Mode를 포함하며, 캐시를 사용할 수 없을 때도 요청이 상위 제공자에게 계속 전달되도록 fail-open 설계를 지원합니다.
주요 기능
- AI SDK에서
fetch: withSemanticGuard()를 통해 한 줄로 SDK 통합이 가능해, 팀이 애플리케이션 로직을 다시 작성하지 않고도 캐싱을 추가할 수 있습니다. - 요청별 비용, 예상 절감액, 히트 유형, 그리고 어떤 트래픽이 캐시될지 보여주는 Shadow Mode 측정 기능으로, 캐시 응답을 제공하기 전에 확인할 수 있습니다.
- 다층 검증을 사용하는 자체 검증 캐시 히트와, 샘플링된 히트에 대한 AI 판정 및 실패 플래그 표시 기능을 제공합니다.
- OpenAI, Anthropic, Google은 물론 Azure, Bedrock, Mistral 같은 다른 기재된 제공자까지 아우르는 크로스 프로바이더 지원을 제공합니다.
- 의미상 일치를 기준으로 캐시 동작이 조정되어 있어, 이름·날짜·ID가 달라도 답변이 사실상 같으면 히트될 수 있습니다.
- 캐시가 다운되면 트래픽을 바로 제공자에게 보내는 fail-open 요청 처리를 지원합니다.
- 사이트에 명시된 보안 제어로는 전송 중 및 저장 시 암호화, 선택적 프롬프트 저장, 그리고 저장하지 않고 요청 시점에 전달되는 상위 API 키가 있습니다.
SemanticGuard 사용 방법
개발자는 withSemanticGuard()로 fetch 레이어를 감싸 AI SDK 설정에 SemanticGuard를 추가한 뒤, 평소처럼 요청을 보냅니다. 사이트에 표시된 흐름은 Shadow Mode로 시작해 절감액을 측정하고 트래픽이 어떻게 분류될지 관찰하는 방식입니다.
팀이 결과에 만족하면 캐싱을 활성화할 수 있습니다. 이때부터는 캐시 히트가 자동으로 반환되며, 대시보드에서 절감액, 히트율, 검증 결과를 확인할 수 있습니다.
사용 사례
- 많은 사용자가 겹치는 질문을 하고 반복 답변을 재사용할 수 있는 대규모 LLM 애플리케이션의 비용 절감
- 특히 캐시된 출력을 바로 제공하지 않고도 절감액을 수치화하고 싶은 팀을 위한, 배포 전 캐싱 경제성 측정
- 이름, 날짜, ID처럼 표면적 세부정보만 다른 의미상 유사한 요청 처리, 이때 바이트 단위로 동일해야 하는 제공자 캐싱은 놓칠 수 있음
- 서로 다른 모델 벤더를 아우르는 단일 캐싱 계층이 필요한 멀티 프로바이더 AI 스택 지원
- 캐싱 계층을 사용할 수 없을 때 대체 경로가 필요한 프로덕션 앱의 가용성 유지
FAQ
SemanticGuard는 프롬프트 변경이 필요한가요? 아니요. 사이트는 한 줄 SDK 통합을 설명하며 프롬프트 변경이 필요 없다고 말합니다.
캐시 히트를 활성화하기 전에 절감액을 테스트할 수 있나요? 네. SemanticGuard에는 캐시된 응답을 제공하기 전에 무엇을 절감할 수 있는지 측정하는 Shadow Mode가 포함되어 있습니다.
한 가지 이상 모델 제공자와 함께 작동하나요? 네. 페이지에는 OpenAI, Anthropic, Google이 나열되어 있으며, Azure, Bedrock, Mistral 같은 다른 제공자와의 호환성도 언급합니다.
캐시를 사용할 수 없으면 어떻게 되나요? 이 제품은 fail-open으로 설명되며, 요청은 직접 제공자에게 전달됩니다.
이 제품은 정확히 일치하는 캐싱만 지원하나요? 아니요. 페이지는 SemanticGuard를 semantic caching으로 소개하며, 이름, 날짜, ID 같은 세부 정보가 바뀌어도 의미가 같다면 대상이 된다고 설명합니다.
대안
- OpenAI나 유사 벤더의 내장 캐싱처럼 제공자 기본 프롬프트 캐싱. 보통 제공자 자체 시스템 내에서 정확 일치 또는 거의 동일한 접두사 재사용에 제한되며, 정적인 프롬프트 구간에 더 적합합니다.
- 애플리케이션이나 프록시에 직접 넣는 수동 캐시 계층. 맞춤화는 가능하지만, 캐시 키 정의, 무효화 관리, 정확성 검증을 위해 더 많은 엔지니어링 작업이 필요합니다.
- 의미 검증이 없는 일반 AI 게이트웨이. 라우팅, 관측성, 정책 집행은 처리할 수 있지만, 정확성 검사를 동반한 캐싱에 반드시 초점을 두지는 않습니다.
- 캐시 계층 없이 직접 제공자를 사용하는 방식. 가장 단순하지만, 유사 요청 간 재사용이나 출시 전 절감액 측정 워크플로우는 추가하지 않습니다.
대안
AakarDev AI
AakarDev AI는 원활한 벡터 데이터베이스 통합을 통해 AI 애플리케이션 개발을 간소화하는 강력한 플랫폼으로, 신속한 배포와 확장성을 가능하게 합니다.
Ably Chat
Ably Chat은 실시간 채팅 API와 SDK로 맞춤형 채팅 앱을 구축합니다. 반응, 존재감, 메시지 편집/삭제를 포함해 대규모 실시간에 최적화
BookAI.chat
BookAI는 제목과 저자를 제공하기만 하면 AI를 사용하여 책과 대화할 수 있게 해줍니다.
DeepMotion
DeepMotion은 웹 브라우저에서 비디오(및 텍스트)로부터 3D 애니메이션을 생성하는 AI 모션 캡처·바디 트래킹 플랫폼입니다. Animate 3D API 지원.
skills-janitor
skills-janitor로 Claude Code 기술을 감사하고 사용량을 추적하며, 9가지 슬래시 커맨드로 자신의 능력을 비교하세요. 의존성 0.
Arduino VENTUNO Q
Arduino VENTUNO Q는 로보틱스용 엣지 AI 컴퓨터로, AI 추론 하드웨어와 마이크로컨트롤러 제어를 한 보드에 통합합니다. Arduino App Lab로 개발 워크플로 제공