面向生产的 RAG
Agentset 面向生产级 RAG 构建,重点关注可靠答案、引用和检索质量,而不是仅用于演示的工作流。
Agentset 是一个开源平台,用于在私有或内部知识库之上构建 AI 聊天和搜索体验。它面向希望获得可直接用于生产的 RAG、而无需自行构建和维护整套检索管线的开发者。
该产品强调可靠回答、引用以及对真实世界文档的支持。首页突出展示了跨文本、图像、图形和表格的多模态检索,而定价页则列出了免费使用、生产应用和企业部署的不同层级。
Agentset 面向生产级 RAG 构建,重点关注可靠答案、引用和检索质量,而不是仅用于演示的工作流。
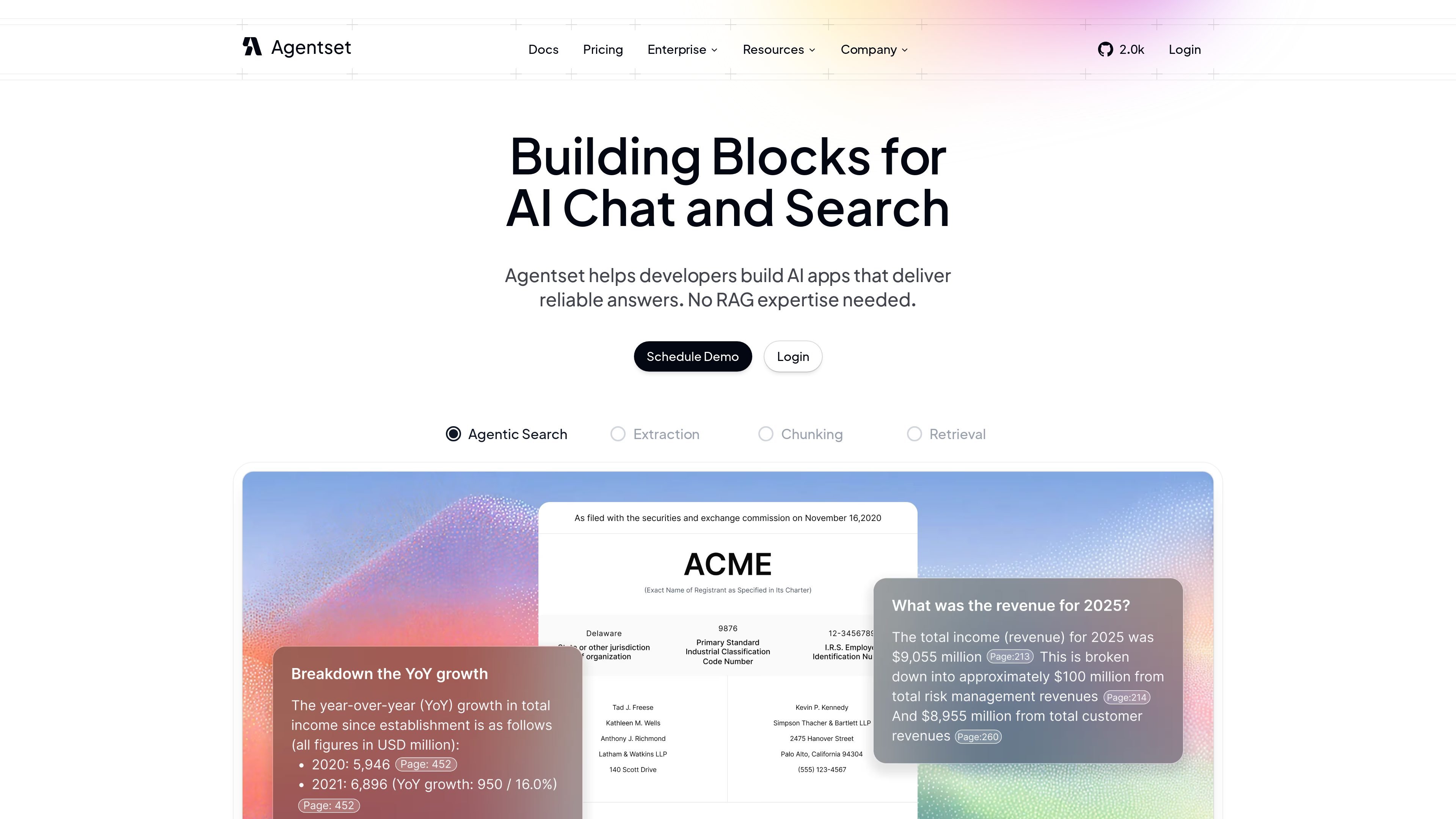
平台支持图像、图表和表格,以及文本内容,使用户可以在更丰富的文档集合中提问。
答案可包含来源引用,便于用户查看回复来源并检查支撑材料。
元数据过滤器可让团队在需要范围受限的答案时,将检索限定到内容子集。
开发者可以通过 JavaScript 和 Python SDK 摄取内容,并支持 22+ 文件格式以及用于外部应用的 MCP server。
Agentset 可与 AI SDK 集成,并允许团队自行选择向量数据库、嵌入模型和 LLM。
在内部文档和知识库之上构建聊天或搜索层,答案需要引用和受控检索,而不是通用聊天机器人回复。
索引包含 PDF、HTML 页面、办公文件和其他支持格式的文档库,然后让用户通过过滤和来源追踪进行搜索。
连接 Google Drive、SharePoint 或 Notion 等外部来源,使内容随着这些系统变化而与知识库保持同步。
当你需要在更大的产品中加入检索层时,可通过 MCP server 或 AI SDK 集成将同一知识库暴露给其他应用。
适用于需要生产部署选项、自定义工作流或企业支持,而不是单一用途原型的团队。
Agentset 是面向开发者的基础设施产品,用于构建生产就绪的 RAG 应用。首页将其描述为用于产品内搜索和问答的平台,定价页则展示了个人使用、生产应用和企业工作流的方案。
来源没有展示详细的安装流程,但确实提供了 JavaScript 和 Python SDK、MCP server 以及 AI SDK 集成,这表明它旨在接入现有开发栈。
Agentset 支持基于文件的摄取,覆盖多种常见格式,包括文本、HTML、PDF 和办公文档,同时也支持 Google Drive、SharePoint 和 Notion 等服务的外部数据连接器。
是的。定价页包含 Free 方案、面向生产应用的 Pro 方案,以及带有自定义工作流和部署选项的 Enterprise 方案。网站还说明方案可以升级或降级。
来源显示,Agentset 可以随答案返回引用和来源参考,并支持元数据过滤、混合搜索、重排序,以及图像、图表和表格等多模态内容。
AakarDev AI 帮助团队在一个仪表板中管理 AI provider 访问、项目级设置、日志和分析,支持 BYOK 工作流,并涵盖 OpenAI、Google Gemini、Anthropic、Groq、Mistral AI 和 Perplexity AI。
ByteAsk 是面向 C 和 C++ 的终端优先 AI 编码 agent,可直接编辑仓库,并在展示 diff 前用真实编译器、调试器、sanitizers 和测试验证修改。提供免费版与付费方案。
Codex Plugins 将可复用技能、应用集成和 MCP 服务器打包为工作流,可在 Codex 应用中安装或通过 Codex CLI 使用,帮助扩展连接服务任务、复用指令和团队共享流程。
hob 是面向编码 agent 的独立工作区,可将 agent 会话、终端、历史记录和后续工作围绕你已在用的工具与提供商有序管理,适合重视本地路由、历史和工作区结构控制的开发者。
Ably Chat 是用于构建自定义实时聊天应用的 chat API 平台,支持房间消息、输入指示、在线状态、表情回应与消息更新,并提供按使用量计费选项。
Wallie 是一款开源 AI 直播助手,能观看屏幕、聆听聊天并以可配置人设生成实时解说。支持本地运行、使用自有密钥,适合无真人出镜内容、自动化直播和实时互动。