端到端模型适配
用户可以用自然语言描述任务,让 Pioneer 端到端构建微调模型,包括数据获取、评估设置、数据整理、训练和发布检查。
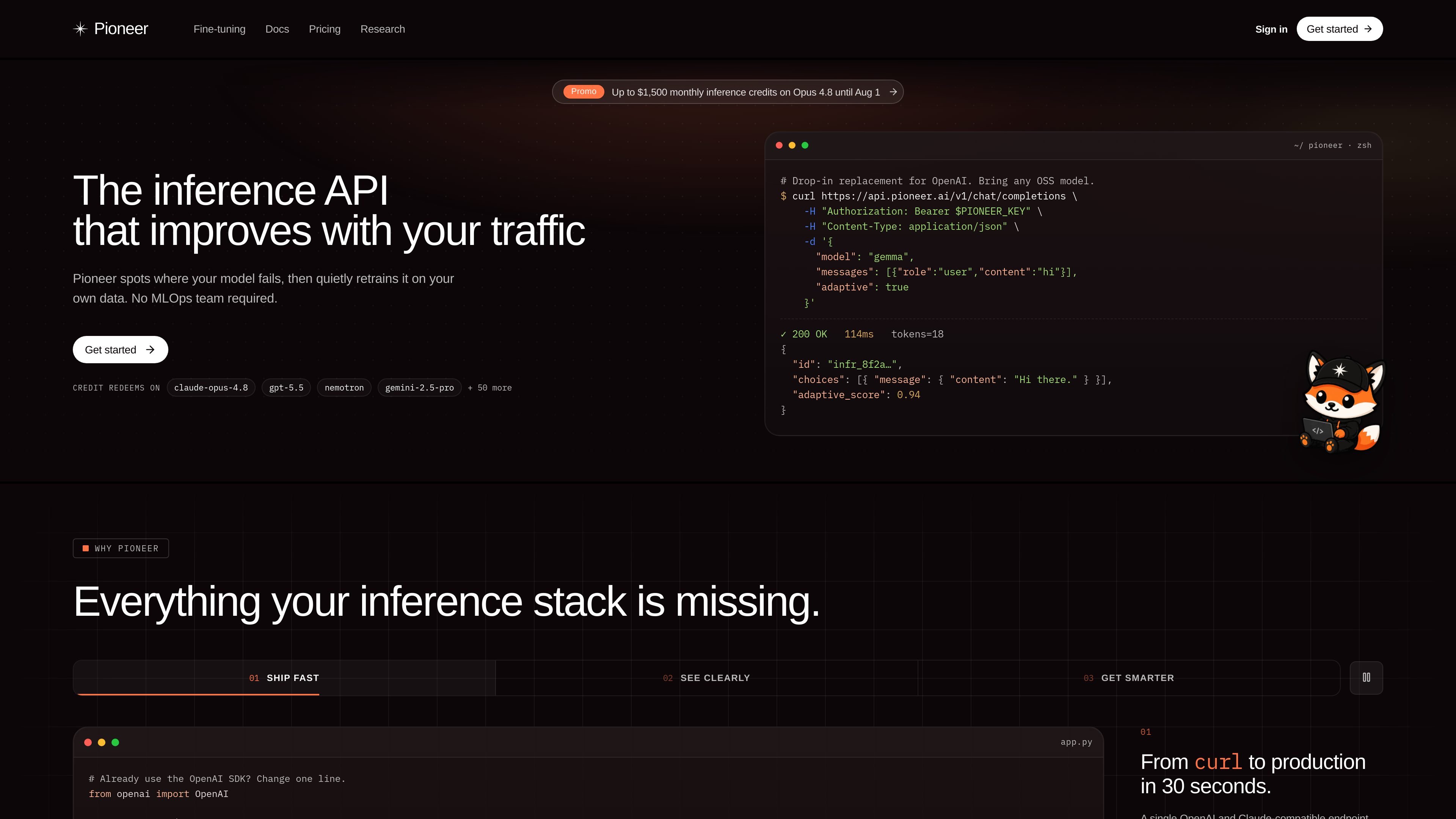
Fastino Labs 出品的 Pioneer AI 是一款用于微调和运行开源语言模型的 agent。其核心工作是接收任务描述,将其转化为已训练模型,并在部署后根据真实使用情况持续改进该模型。
该产品围绕小型语言模型和结构化 AI 工作流构建,例如分类和抽取。网站将 Pioneer 定位为一种无需搭建手工训练流水线或管理庞大 MLOps 栈即可获得可直接上线模型行为的方式。
用户可以用自然语言描述任务,让 Pioneer 端到端构建微调模型,包括数据获取、评估设置、数据整理、训练和发布检查。
部署后,Pioneer 可以针对实时推理数据持续改进模型,并利用生产反馈推动后续优化。
该产品面向开源 SLM 和 LLM,示例包括 Qwen、Gemma、Llama 和 GLiNER。
来源称 Pioneer 搜索的是完整训练流水线,而不仅仅是超参数,会同时考虑数据构成、学习策略和训练设置。
定价和上线文案提到 Pro 方案支持下载模型权重和团队邀请,说明其支持将结果输出到托管工作流之外。
网站展示了一个研究到生产的闭环,可诊断失败、构建纠正性课程、重新训练,并且只发布通过评估的更新。
团队可以描述像 PII 检测或意图分类这样的任务,让 Pioneer 负责搭建训练流程、评估候选模型,并产出可部署的模型。
在部署后,团队可以把来自实时流量的已判定失败反馈回系统,让 Pioneer 诊断模式并结合回归约束重新训练。
处理结构化文本问题的团队可以将 Pioneer 用于分类、抽取、NER 以及类似工作负载;这类场景通常需要小模型既快又准。
希望避免自建训练基础设施的组织可以使用托管工作流和分层方案,而不必拼接多个独立的 MLOps 工具。
更大的团队可以使用 Pro 或 Enterprise 路径,以获得更高的使用上限、可下载权重、团队访问权限和定制部署安排。
Pioneer 是一款用于微调并运行开源语言模型的 agent。来源描述了两种模式:一种是从任务描述出发进行端到端微调的 Agent 模式,另一种是在生产推理流程中基于实时使用数据持续优化模型。
来源说明 Pioneer 可用于包括 Qwen、Gemma、Llama 和 GLiNER 在内的开源 SLM 和 LLM。它面向希望为分类、抽取及其他生产工作流等结构化任务微调并部署模型的团队。
定价页面显示有 Hobby、Pro 和 Enterprise 方案。Hobby 包含每月推理额度,Pro 提供更高上限并支持购买使用额度,Enterprise 则面向更大团队和更复杂的工作流提供定制方案。
可以。定价页面说明 Pro 方案可包含可下载的模型权重、团队邀请和更大的使用额度。产品还描述了适合团队在训练与生产推理之间持续迭代的工作流。
现有来源未提供完整的上手指南、API 参考或部署矩阵。但这些资料表明该产品旨在减少手工训练和 MLOps 工作,只是具体实现细节在收集到的页面中并未完整说明。
AakarDev AI helps teams manage AI provider access, project-level setups, logs, and analytics from one dashboard. It supports BYOK workflows and lists providers including OpenAI, Google Gemini, Anthropic, Groq, Mistral AI, and Perplexity AI.
Benchspan is an AI agent security platform that discovers agents, blocks prompt injection and data exfiltration in real time, and supports pre-launch red teaming. It is aimed at teams running agents in production and includes Python and TypeScript SDKs.
Edgee is an AI gateway for coding agents and LLM-powered apps. It compresses token traffic, routes requests across models, and provides observability and team controls to help reduce cost and keep sessions running.
LobeHub is an agent collaboration platform for work and productivity. It supports multi-agent workflows, persistent memory, and cloud-based model usage across web, desktop, mobile, and CLI surfaces.
Codex Plugins bundle reusable skills, app integrations, and MCP servers into workflows you can install in the Codex app or use from Codex CLI. They help extend Codex with connected-service tasks, reusable instructions, and shared team workflows.
Wallie 是一款开源 AI 直播助手,能观看屏幕、聆听聊天并以可配置人设生成实时解说。支持本地运行、使用自有密钥,适合无真人出镜内容、自动化直播和实时互动。