以生產環境為導向的 RAG
Agentset 以正式上線的 RAG 為設計重點,著重於可靠答案、引用與檢索品質,而非僅供展示的流程。
Agentset 是一個開源平台,可在私有或內部知識庫之上打造 AI 聊天與搜尋體驗。它適合想要直接使用可正式上線的 RAG,而不必自行建立與維護整套檢索管線的開發者。
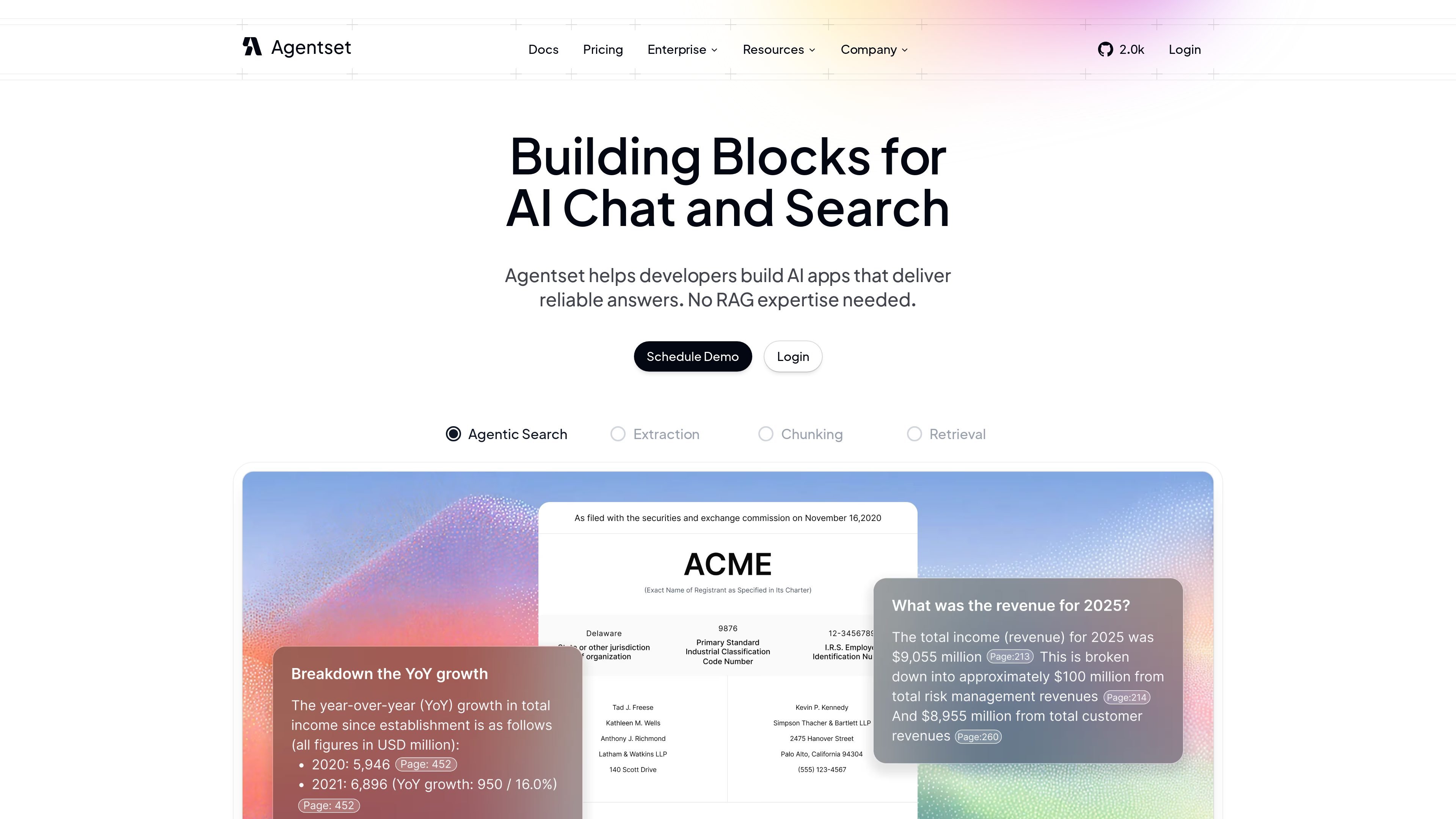
這個產品強調可靠答案、引用,以及對真實世界文件的支援。首頁強調可跨文字、圖片、圖表與表格進行多模態檢索,而定價頁面則顯示其提供免費使用、生產應用與企業部署的分級方案。
Agentset 以正式上線的 RAG 為設計重點,著重於可靠答案、引用與檢索品質,而非僅供展示的流程。
平台支援圖片、圖表與表格等內容,並可搭配文字一起檢索,讓使用者能跨更豐富的文件集合提問。
答案可附上來源引用,讓使用者能查看回覆來源並檢視支撐材料。
metadata 篩選可讓團隊在需要範圍限定的答案時,將檢索縮小至內容子集合。
開發者可透過 JavaScript 與 Python SDK 匯入內容,並支援 22+ 種檔案格式與供外部應用使用的 MCP 伺服器。
Agentset 可與 AI SDK 整合,並讓團隊自行選擇向量資料庫、嵌入模型與 LLM。
在內部文件與知識庫之上建立聊天或搜尋層,當答案需要引用與受控檢索,而非一般聊天機器人回覆時使用。
索引包含 PDF、HTML 頁面、Office 檔案與其他支援格式的文件庫,再讓使用者透過篩選與來源追蹤進行搜尋。
連接 Google Drive、SharePoint 或 Notion 等外部來源,讓內容在這些系統變動時仍能與知識庫保持同步。
當你需要在更大型產品內使用檢索層時,透過 MCP 伺服器或 AI SDK 整合,將同一個知識庫暴露給其他應用程式。
適合需要生產部署選項、自訂工作流程或企業支援,而非單一用途原型的團隊。
Agentset 是供開發者打造可正式上線的 RAG 應用程式的基礎架構產品。首頁將其描述為可在產品內進行搜尋與問答的平台,而定價頁面則顯示其提供個人使用、生產應用與企業工作流程方案。
來源未提供詳細的設定流程,但有展示 JavaScript 與 Python SDK、MCP 伺服器,以及 AI SDK 整合,這表示它設計上可接入既有的開發堆疊。
Agentset 支援多種常見格式的檔案匯入,包括文字、HTML、PDF 與 Office 類文件,也支援 Google Drive、SharePoint 與 Notion 等服務的外部資料連接器。
可以。定價頁面包含 Free 方案、適用於生產應用的 Pro 方案,以及提供自訂工作流程與部署選項的 Enterprise 方案。網站也說明方案可以升級或降級。
來源顯示 Agentset 可隨答案傳回引用與來源參考,並支援 metadata 篩選、hybrid search、reranking,以及圖片、圖表和表格等多模態內容。
AakarDev AI 讓團隊透過單一儀表板管理 AI 供應商權限、專案設定、日誌與分析,支援 BYOK 工作流程,並可連接 OpenAI、Google Gemini、Anthropic、Groq、Mistral AI、Perplexity AI。
CreateOS Sandbox 是以 Firecracker micro-VM 執行程式與 agent 工作負載的隔離運算環境,支援私有網路、SDK、CLI 與 MCP 程式化控制。
ByteAsk 是專為 C 與 C++ 打造的終端機優先 AI coding agent,先編輯儲存庫再用真實編譯器、除錯器、sanitizer 與測試驗證變更,並提供免費方案與付費方案。
Codex Plugins 將可重用技能、應用程式整合與 MCP 伺服器打包成可安裝到 Codex app 或在 Codex CLI 使用的工作流程,方便延伸 Codex 的連線服務任務、重複使用指令與團隊共享流程。
hob 是一個獨立的 coding agents 工作區,整合 agent sessions、終端機、歷史紀錄與後續工作,並維持你既有的工具與供應商設定。適合想保有本機路由、歷史與工作區結構控制權的開發者。
Ably Chat 是一個聊天 API 平台,適合打造自訂即時聊天應用程式。支援聊天室訊息、輸入中提示、在線狀態、表情回應與訊息更新,並提供依使用量計費選項。