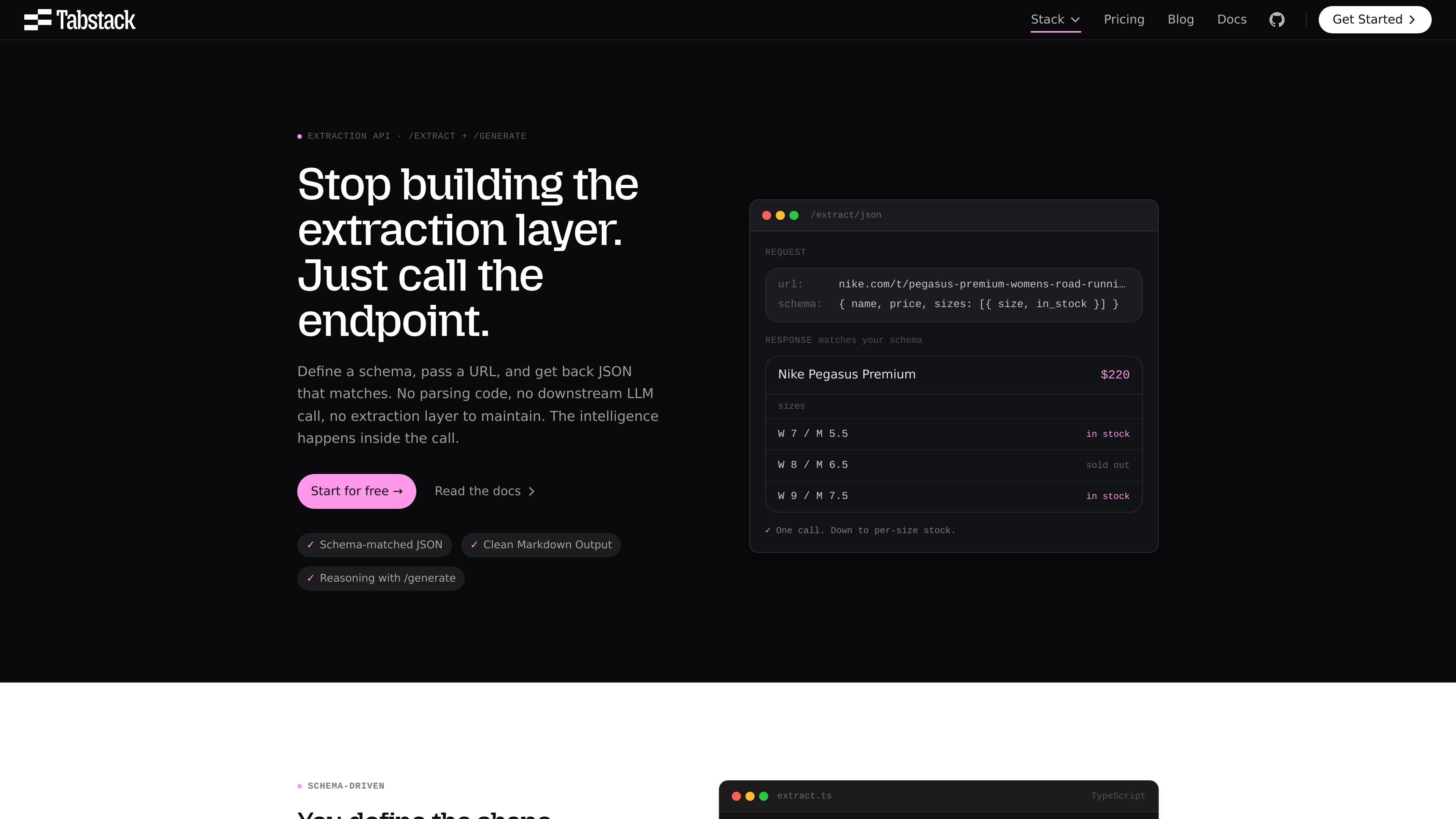
以 schema 驅動的擷取
定義你需要的 JSON 結構並傳入 URL。Tabstack 在伺服器端強制套用 schema,並回傳符合該 schema 的輸出,即使來源頁面有所變動也是如此。
Tabstack 的 Structured Data Extraction API 可將 URL 轉為符合你定義 schema 的 JSON。此產品專為需要從網頁取得一致結構化輸出的團隊設計,讓他們無需維護自己的解析邏輯、瀏覽器流程或下游 LLM 協調。
網站頁面展示了兩個密切相關的工作流程:`/extract/json` 用於直接進行符合 schema 的擷取,而 `/generate/json` 則適用於需要在頁面內容之上加入指令與推理的情境。同一平台也提供 Markdown 輸出、帶引用的研究,以及瀏覽器自動化,但本頁聚焦於結構化擷取的使用情境。
定義你需要的 JSON 結構並傳入 URL。Tabstack 在伺服器端強制套用 schema,並回傳符合該 schema 的輸出,即使來源頁面有所變動也是如此。
可使用 `/extract/json` 取得固定結構資料,使用 `/extract/markdown` 取得頁面文字,或在需要於來源頁面上疊加指令時使用 `/generate/json`。
網站說明此擷取功能可用於伺服器渲染、客戶端渲染與 JavaScript 較重的頁面,因此流程不侷限於靜態 HTML。
`/generate/json` 會將指令加入以 URL 為基礎的流程中,適合需要解讀而非單純欄位擷取的任務。
可透過 `nocache`、`effort` 與 `geo_target` 控制新鮮度與擷取行為,包括即時抓取與特定國家視角。
產品範例中展示了 TypeScript SDK,而定價頁也列出 Python SDK、MCP 與 CLI,作為整個平台的存取選項。
將價格表、產品規格、庫存狀態或其他頁面資料擷取成固定的 JSON 結構,用於儀表板與下游系統。
將網域或產品頁轉為標準化的公司、產品或聯絡人資料,用於資料增補流程。
使用結構化 JSON 或 Markdown 將產品頁、文件與文章導入檢索或索引流程,而不必撰寫自訂爬取程式。
當僅靠頁面內容不足以完成任務,且結果需要結構化解讀時,可使用 `/generate/json`,例如說明定價頁對分層方案可能暗示的意義。
對於需要相鄰工作流程的團隊,同一平台也支援帶引用的網路研究與即時頁面的瀏覽器自動化。
可以。來源頁面顯示了 TypeScript SDK,以及用於 extraction 和 research 端點的範例呼叫,並且文件中也記錄了 `/extract/json`、`/extract/markdown`、`/generate/json`、`/research` 和 `/automate` 這些 API 端點。
結構化擷取流程是針對 URL 搭配 JSON schema 設計的。Tabstack 會回傳符合該 schema 的 JSON,網站也展示了相關的 `/generate/json` 流程,用於以指令為基礎的結構化輸出。
首頁顯示它可在伺服器渲染、客戶端渲染,以及 JavaScript 較重的頁面上進行擷取。也提到在需要時可輸出乾淨的 Markdown。
網站上有公開的定價資訊:包含 10,000 credits 的免費試用、Individual 方案、含額度的 Team 與 Pro 方案,以及採客製化定價的 Enterprise 方案。
來源資料未說明已公開的 SDK、驗證方式,或除了頁面範例之外的輸出格式清單。文件中最明確記載的輸出包括符合 schema 的 JSON、乾淨的 Markdown、帶引用的研究回覆,以及已完成的瀏覽器任務。
Happenstance 是一款 AI 網路搜尋工具,可跨已連結帳號搜尋人脈、共同聯絡人與暖身介紹,並支援個人、團隊群組、API、MCP、Slack 等整合。
Geekflare Web Scraping API 是開發者專用網頁爬取服務,可擷取動態頁面內容並輸出 Markdown、HTML、JSON 或純文字,支援瀏覽器渲染、CAPTCHA 處理與代理伺服器。
nolainocr 是一款 AI OCR 工具,可從 PDF 發票、收據、表單、合約與銀行對帳單擷取結構化資料,快速匯出至 Excel、Google Sheets、JSON 或 CSV,免手動輸入。
Octen 是一款為 AI 應用打造的搜尋基礎架構,提供即時網頁上下文、結構化回答與檢索工具,適用於 agents、copilots 與 chatbots,並支援 API、SDK、Skills、MCP、CLI。
Skayle 是內容與 AI 搜尋可見度平台,先做主題研究再撰寫,並將結構化內容發布到 CMS,追蹤品牌是否被 AI 搜尋引用。適合想用單一系統管理發布、Schema 內容與可見度監測的團隊。
司马阅是企業級AI文件智能體平台,協助團隊將分散於文件中的知識轉為可用於問答、檢索、撰寫與審查的結構化能力,適合重視準確性與資料安全的企業。