End-to-end model adaptation
Users can describe a task in natural language and let Pioneer build a fine-tuned model end to end, including data acquisition, evaluation setup, curation, training, and promotion checks.
Pioneer AI is an agent for fine-tuning and continuously improving open-source language models. It helps teams build production-ready models for tasks like classification and extraction without assembling a manual training pipeline.
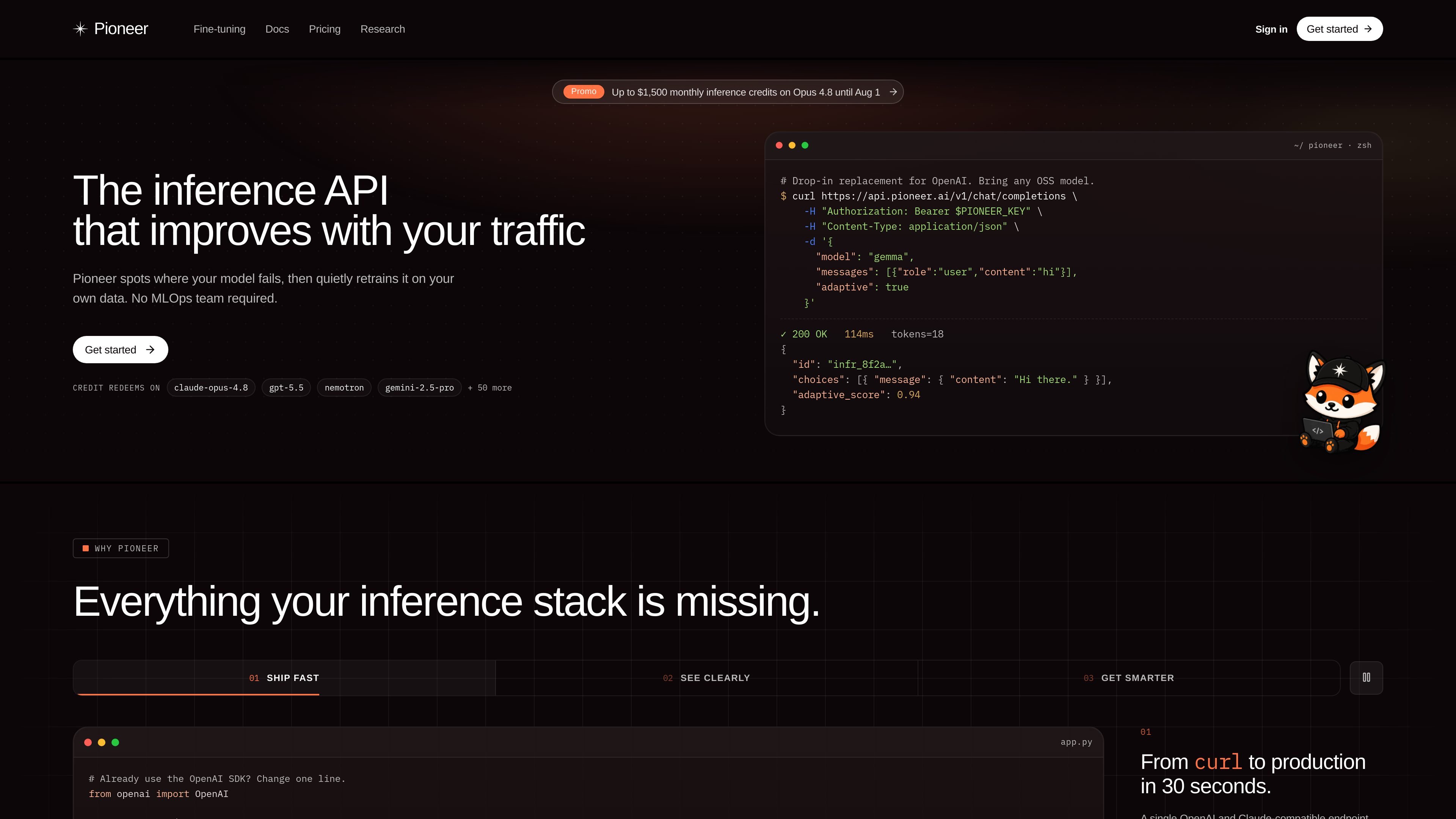
Pioneer AI by Fastino Labs is an agent for fine-tuning and running open-source language models. Its core job is to take a task description, turn it into a trained model, and then keep improving that model from real usage once it is deployed.
The product is built around small language models and structured AI workflows such as classification and extraction. The site positions Pioneer as a way to get production-ready model behavior without building a manual training pipeline or managing a large MLOps stack.
Users can describe a task in natural language and let Pioneer build a fine-tuned model end to end, including data acquisition, evaluation setup, curation, training, and promotion checks.
When deployed, Pioneer can continue improving a model against live inference data, using production feedback to drive further optimization over time.
The product is positioned for open-source SLMs and LLMs, with examples including Qwen, Gemma, Llama, and GLiNER.
The source says Pioneer searches over full training pipelines rather than only hyperparameters, taking into account data composition, learning strategy, and training settings.
Pricing and launch copy mention downloadable model weights and team invites on Pro, which suggests support for shipping outputs beyond a hosted workflow.
The site presents a research-and-production loop that can diagnose failures, build corrective curricula, retrain, and only promote updates that pass evaluation.
A team can describe a task like PII detection or intent classification and let Pioneer assemble the training loop, evaluate candidates, and produce a deployable model.
After deployment, teams can feed judged failures from live traffic back into the system so Pioneer can diagnose patterns and retrain with regression constraints.
Teams working on structured text problems can use Pioneer for classification, extraction, NER, and similar workloads where small models are expected to be fast and accurate.
Organizations that want to avoid building their own training infrastructure can use the hosted workflow and tiered plans instead of stitching together separate MLOps tools.
Larger teams can use the Pro or Enterprise path for higher usage limits, downloadable weights, team access, and custom deployment arrangements.
Pioneer is an agent for fine-tuning and running open-source language models. The source describes two modes: an Agent mode for end-to-end fine-tuning from a task description, and a production inference flow where models are continuously optimized from live usage data.
The source says Pioneer can work with open-source SLMs and LLMs including Qwen, Gemma, Llama, and GLiNER. It is positioned for teams that want to fine-tune and deploy models for structured tasks such as classification, extraction, and other production workflows.
The pricing page shows Hobby, Pro, and Enterprise plans. Hobby includes monthly inference allowance, Pro adds higher caps and the option to purchase usage credits, and Enterprise is custom for larger teams and complex workflows.
Yes. The pricing page says Pro plans can include downloadable model weights, team invites, and larger usage allowances. The product also describes a workflow for teams that iterate on training and production inference.
The available sources do not provide a full setup guide, API reference, or deployment matrix. They do indicate that the product is designed to reduce manual training and MLOps work, but specific implementation details are not fully documented in the collected pages.
AakarDev AI helps teams manage AI provider access, project-level setups, logs, and analytics from one dashboard. It supports BYOK workflows and lists providers including OpenAI, Google Gemini, Anthropic, Groq, Mistral AI, and Perplexity AI.
Benchspan is an AI agent security platform that discovers agents, blocks prompt injection and data exfiltration in real time, and supports pre-launch red teaming. It is aimed at teams running agents in production and includes Python and TypeScript SDKs.
Edgee is an AI gateway for coding agents and LLM-powered apps. It compresses token traffic, routes requests across models, and provides observability and team controls to help reduce cost and keep sessions running.
LobeHub is an agent collaboration platform for work and productivity. It supports multi-agent workflows, persistent memory, and cloud-based model usage across web, desktop, mobile, and CLI surfaces.
Codex Plugins bundle reusable skills, app integrations, and MCP servers into workflows you can install in the Codex app or use from Codex CLI. They help extend Codex with connected-service tasks, reusable instructions, and shared team workflows.
Wallie is an open-source AI streamer that watches your screen, hears chat, and generates live commentary in a configurable persona. It runs locally on your machine with your own keys and is aimed at faceless content, autonomous streams, and real-time reactions.