SQLite 互換でリージョン拡張可能なデータベース
bunny.net のネットワーク上に SQLite 互換データベースを作成し、1つのリージョンから開始して、アプリケーション設計を変えずに後からリージョンを追加できます。
bunny.netのSQLite互換DBaaS「Bunny Database」。読み取り中心のアプリ向けに、低遅延で地域横断のアクセスとlibSQL SDK、HTTP接続、従量課金、無料公開プレビューに対応。
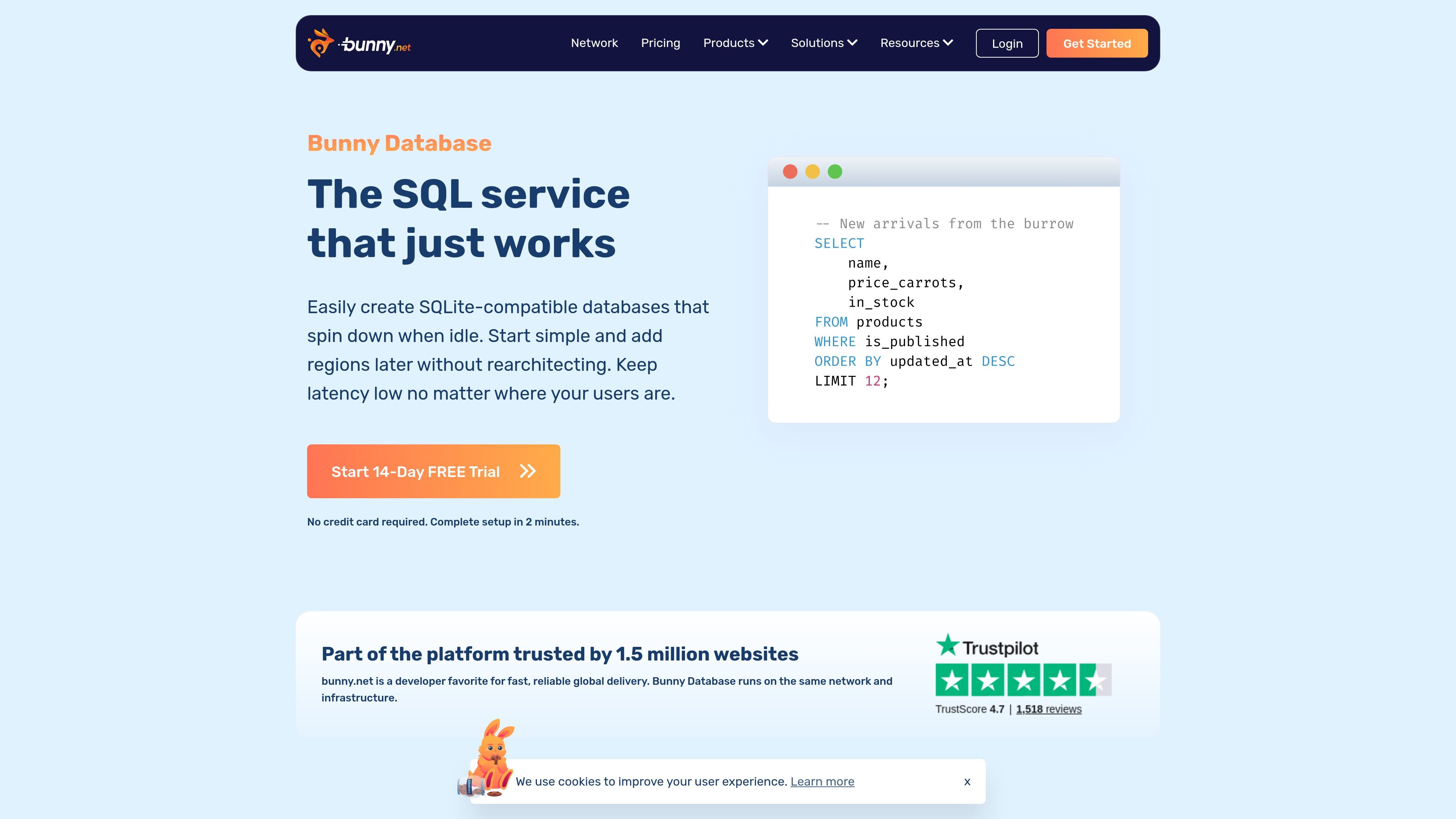
Bunny Database は、bunny.net が提供する SQLite 互換のデータベースサービスです。アイドル時には停止し、1つのリージョンから開始して、後から再設計を強いられることなく複数のリージョンへ拡張できるよう設計されています。
この製品は、地理的に分散した環境でも低レイテンシーを必要とする読み取り中心のアプリケーション向けのシンプルな DBaaS として位置づけられています。bunny.net のグローバルネットワーク上で動作し、TS/JS、Go、Rust、.NET 向けの使い慣れた libSQL SDK を公開しており、必要に応じて HTTP アクセスも利用できます。
bunny.net のネットワーク上に SQLite 互換データベースを作成し、1つのリージョンから開始して、アプリケーション設計を変えずに後からリージョンを追加できます。
41 のリージョンから選択し、ユーザーにより近い場所で読み取りを提供することで、分散した利用者に対する往復時間を短く保てます。
TS/JS、Go、Rust、.NET 向けの公式 libSQL SDK を利用するか、より汎用的なインターフェースが必要な場合は HTTP で接続できます。
テーブルを確認し、SQL を実行し、データを直接確認できるため、別の管理ツールを行き来する必要がありません。
データベースのスケールに合わせてレイテンシー、トラフィック、ストレージを追跡し、利用状況の変化を把握できます。
データベースがアイドル状態のときは、ソースによればストレージ費用のみが発生し、read replica はトラフィックを処理しているときのみストレージ費用が追加で発生します。
ユーザーが更新する頻度よりも閲覧する頻度の高い、構造化されたカタログデータ、所在地一覧、ディレクトリ内容を保存します。
タグ、カテゴリ、その他の参照データを、重いデータベース負荷なしでフィルタリングや並べ替えに利用できるように保持します。
シンプルなリレーショナルストレージを必要とするアプリケーション向けに、アカウント設定、各種設定、軽量なユーザーごとの状態を提供します。
変更頻度の低いアプリケーション、テナント、環境の設定を一元化し、トラフィックの拡大に合わせて後からリージョンを追加できます。
SQL の確認や、レイテンシー、トラフィック、ストレージの追跡を、別の運用スタックに移行せずに行いたいチームを支援します。
Bunny Database は、bunny.net のグローバルネットワーク上にある SQLite 互換のデータベースサービスです。ソースでは、低遅延アクセス向けに設計されており、1つのリージョンで開始し、後から再設計なしで複数のリージョンへ拡張できると説明されています。
ソースによると、TS/JS、Go、Rust、.NET 向けのおなじみの libSQL SDK で接続でき、必要に応じて HTTP も使用できます。アクセス トークンは環境変数として利用でき、一般的なアプリやスクリプトの構成に適しています。
カタログやディレクトリ、メタデータやフィルタリング、ユーザープロファイル、アプリ設定など、読み取り中心のワークロード向けに位置づけられています。ページでは、読み取り中心のユースケースに最適であると明記されています。
料金セクションでは、使用量に応じて継続的に課金され、月単位で請求されること、また読み取り、書き込み、ストレージが別々に課金されることが示されています。さらに、Bunny Database は公開プレビュー中は無料とされています。
ページでは、利用可能な 41 のリージョン、read replica、そしてレイテンシー、トラフィック、ストレージの指標に言及しています。また、Bunny Database は単体で動作し、Edge Scripting や Magic Containers と組み合わせられるとも説明されています。
NodeDBは、リレーショナル、ベクトル、グラフ、ドキュメント、カラム型、科学配列データを1つのRustバイナリで統合するユニバーサルデータベースエンジン。PostgreSQLクライアント互換と、ベクトル検索とグラフ展開を1回のクエリで融合するGraphRAG風ワークフローに対応。
Metabase Data Studioは、Metabase内で再利用可能なデータを整備・定義・公開するためのセマンティックレイヤー兼分析ワークベンチです。メトリクス、依存関係、厳選データセットを一貫して保ち、セルフサービス分析や埋め込み分析を支援します。
NewsCatcher Platformは、Web検索結果からカスタムニュースデータセットを生成し、記事を監視できるWebアプリです。分析やAIワークフロー向けに、引用付きの構造化レコードを作成できます。
Happenstanceは、つながったアカウント全体から人脈、共通のつながり、紹介候補を見つけるAIネットワーク検索ツールです。個人利用、チーム共有、API・MCP・Slack連携に対応。
VeerexaのYouTube Comments Exporterは、YouTube動画のコメントをブラウザ上で抽出し、CSVまたはJSONで分析・エクスポートできるツールです。サーバー処理不要で素早く確認できます。
AnySearchは、エージェント向けのAI検索基盤。MCP、Skill、REST APIで構造化結果を返し、最新の機械可読情報を使う自動化ワークフローに最適です。