Multiple data models in one engine
NodeDB is described as combining relational, vector, graph, document, columnar, and scientific array data in a single Rust-based engine.
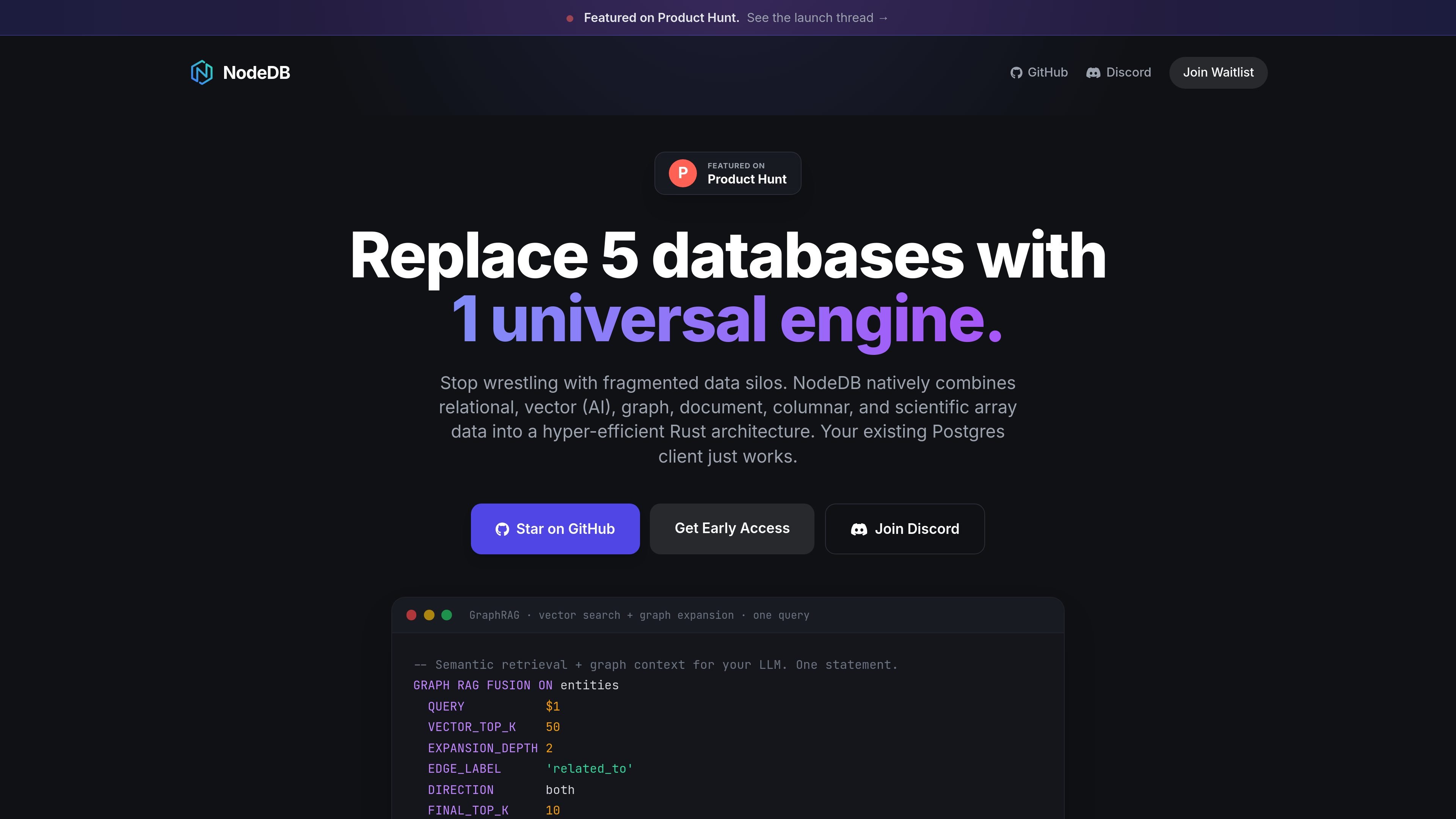
NodeDB is a universal database engine that combines relational, vector, graph, document, columnar, and scientific array data in one Rust binary. It claims PostgreSQL client compatibility and shows a GraphRAG-style workflow that fuses vector search with graph expansion in a single query.
NodeDB is presented as a universal database engine that combines relational, vector, graph, document, columnar, and scientific array data in one Rust binary. The homepage positions it as a way to replace multiple specialized databases with a single system instead of moving data between separate stores.
The product page also emphasizes PostgreSQL client compatibility and shows a GraphRAG-style example where vector search and graph expansion are fused in one query. Based on the supplied pages, NodeDB is aimed at teams that want one database layer for mixed workloads, especially retrieval workflows that need both semantic search and graph context.
NodeDB is described as combining relational, vector, graph, document, columnar, and scientific array data in a single Rust-based engine.
The homepage states that an existing Postgres client just works, indicating compatibility with the PostgreSQL client interface without requiring a new client workflow.
A GraphRAG example shows vector search and graph expansion in one statement, with rank fusion applied at query time.
The product is presented as a Rust binary, which suggests a single executable deployment model rather than a multi-service stack.
The site frames the product around avoiding fragmented data silos and reducing the need for separate pipelines or Python glue for retrieval workflows.
Use NodeDB when you want semantic retrieval and graph neighborhood expansion in one query instead of orchestrating separate vector and graph systems.
Use it for applications that need relational records alongside vectors, graphs, documents, columnar data, or scientific arrays in one engine.
Use it when you already have a Postgres-oriented client and want a database layer that claims compatibility with that client workflow.
Use it when you want a single Rust binary rather than coordinating multiple databases and glue code across services.
NodeDB is presented as a universal engine that combines relational, vector, graph, document, columnar, and scientific array data in one Rust binary. The homepage also says an existing Postgres client works with it.
The homepage highlights GraphRAG-style retrieval that combines vector search and graph expansion in a single query. It shows a fused query example and describes the workflow as running at the database layer without separate pipelines.
The source says existing Postgres clients work, but it does not list specific drivers, APIs, or connectors. Beyond that compatibility claim, no detailed integration matrix is provided on the pages supplied.
A pricing page URL exists, but it currently returns a 404 in the supplied evidence. That means no plan, pricing, or trial details can be confirmed from the available pages.
garden-md is an open-source Node.js CLI that turns meeting transcripts into a local company wiki. It links entities across transcripts, keeps the original text intact, and renders the result as a browsable wiki.
Scite는 논문 검색, 인용 문맥 확인, 학술 문헌에 근거한 답변을 제공하는 AI 연구 플랫폼입니다. 연구자, 학생, 팀의 근거 평가를 돕습니다.
DrDroid is an AI SRE agent that connects to cloud, code, and telemetry sources to build a stack-wide knowledge graph for incident investigation and remediation support. It is aimed at teams that want faster root-cause analysis, shared investigations, and an enterprise path for self-hosted deployments.
Metabase Data Studio is a semantic layer and analytics workbench for cleaning, defining, and publishing reusable data inside Metabase. It helps teams keep metrics, dependencies, and curated datasets consistent for self-service and embedded analytics.
Datix로 스프레드시트 데이터를 분석하세요. CSV/Excel 업로드 또는 Google Drive·Supabase 연결 후, 자연어로 질문하면 구조화된 답·요약·차트를 제공합니다.
Mindspase is a web-based knowledge organizer for saving links, organizing them into Spaces, and rediscovering content with AI-assisted workflows. It also supports collaboration, bookmark import, and customizable viewing modes.