PinchBench란?
PinchBench는 표준화된 코딩 작업에서 성공률로 AI 모델을 순위 매기는 OpenClaw LLM 모델 벤치마킹 사이트입니다. 핵심 목적은 동일한 에이전트 기반 테스트 설정으로 여러 LLM을 비교하여 가정 대신 측정된 결과에 기반해 모델을 선택할 수 있도록 돕는 것입니다.
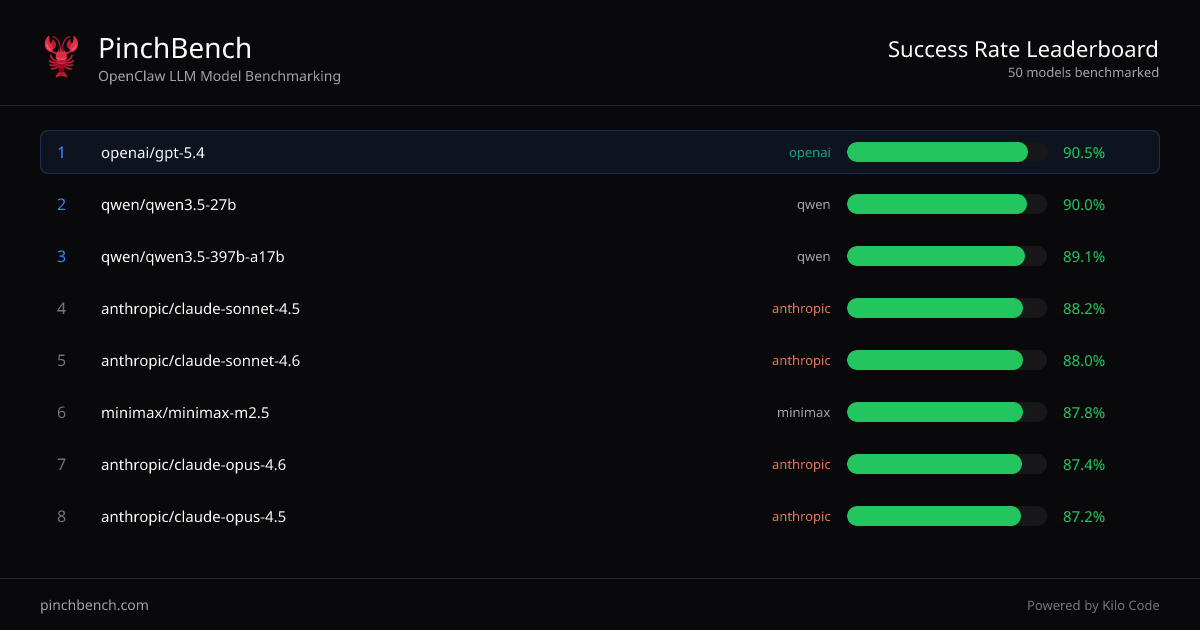
사이트는 “모델별 성공률” 순위를 제시하며 더 많은 작업과 채점 세부 정보를 확인할 수 있습니다. 또한 채점과 점수가 자동 체크와 LLM 심판을 사용한 자동화된 방식임을 표시합니다.
주요 기능
- 모델 간 성공률 순위: “Best %,” “Avg %” 및 관련 점수 열이 포함된 정렬된 모델 테이블을 표시하여 성능을 일관되게 비교합니다.
- OpenClaw 에이전트 벤치마킹: “OpenClaw” 에이전트 워크플로우 맥락에서 모델을 평가하여 에이전트 주도 코딩 작업에서의 모델 성능을 반영합니다.
- 체크와 LLM 심판을 통한 자동 채점: 점수는 자동 체크와 LLM 심판에서 도출되어 반복 가능한 평가 방법을 제공합니다.
- 예산 필터링 (런당 최대 $): 인터페이스에 표시된 “Max $per run” 예산 필터를 포함하여 비용 제약 내에서 비교를 집중할 수 있습니다.
- 투명한 테스트 자료와 기준: “모든 작업과 채점 기준은 오픈 소스”임을 명시하고 작업을 확인할 수 있는 방법을 제공합니다.
PinchBench 사용 방법
- PinchBench로 이동하여 모델 순위 테이블을 사용해 성공률로 모델을 비교합니다.
- 선택적으로 “Max $ per run” 컨트롤을 사용해 예산 필터링을 조정하여 지정된 비용 한도에 맞는 모델로 결과를 좁힙니다.
- 모델 선택 전에 점수가 무엇을 측정하는지 이해하기 위해 작업 뷰와 채점 세부 정보(오픈 채점 기준 포함)를 사용합니다.
사용 사례
- OpenClaw 코딩 에이전트용 LLM 선택: 표준화된 에이전트 작업에서 측정된 성공률로 후보 모델을 비교한 후 사용 사례에 최적의 성능 모델을 선택합니다.
- 최고 품질 vs. 평균 성능 평가: 테이블의 “Best %”와 “Avg %” 열을 사용해 피크 성능이 좋은 모델과 일관된 결과를 내는 모델을 구분합니다.
- 비용 인식 모델 비교: 동일한 벤치마크 작업에 의존하면서 런당 최대 $ 필터를 적용해 예산 상한 내에서 모델을 비교합니다.
- 점수 계산 방식 검토: 벤치마크에서 “성공”이 무엇을 의미하는지 확인하고 예상 동작과 일치하는지 평가하기 위해 오픈 작업과 채점 기준을 확인합니다.
- 단일 뷰에서 여러 제공자 비교: 통합 순위를 사용해 테이블에 표시된 바와 같이 OpenAI, Anthropic, Qwen, Minimax, Google 모델 등 다른 제공자의 모델을 비교합니다.
자주 묻는 질문
-
PinchBench는 모델의 성공률을 어떻게 결정하나요? 성공률은 표준화된 OpenClaw 에이전트 테스트에서 성공적으로 완료된 작업의 백분율로 측정되며, 자동 체크와 LLM 심판을 사용합니다.
-
벤치마크 테스트 내용 확인이 가능하나요? 네. 페이지에서 작업을 확인할 수 있는 옵션을 제공하며, 작업과 채점 기준이 오픈 소스임을 명시합니다.
-
순위에 표시되는 지표는 무엇인가요? 순위 테이블에는 “Best %”와 “Avg %” 등의 성공 관련 백분율 필드(인터페이스에 추가 점수 열 표시)가 포함됩니다.
-
비용으로 모델을 필터링할 수 있나요? 인터페이스에 예산 필터 “Max $per run”이 포함되어 표시 결과를 제한할 수 있습니다.
-
PinchBench는 일반 채팅 품질을 평가하나요? 사이트는 OpenClaw 에이전트 코딩 작업에서 모델을 벤치마킹하며, 표시된 성공률은 해당 표준화된 벤치마크 맥락에 해당합니다.
대안
- 일반 LLM 리더보드: 광범위하고 작업 특화되지 않은 순위는 빠른 스캔에 유용하지만, 일반적으로 OpenClaw 에이전트 코딩 작업 성능을 측정하지 않습니다.
- 자체 평가 하네스 / 내부 벤치마크: 큐레이션된 코딩 작업 세트를 실행하고 자체 채점 방식을 적용하면 요구사항에 더 잘 맞지만, 설정과 지속 관리가 필요합니다.
- 제공자별 평가 및 벤치마크: 일부 벤더가 벤치마크 성능 결과를 게시하지만, 작업 설계와 채점이 PinchBench와 다를 수 있어 비교는 신중히 다뤄야 합니다.
- 에이전트 프레임워크 평가 도구: 에이전트 워크플로우로 LLM을 테스트할 수 있는 도구는 워크플로우 맞춤 결과를 제공하지만, PinchBench와 같은 표준화된 크로스 모델 벤치마크와 오픈 채점 기준을 제공하지 않을 수 있습니다.
대안
AakarDev AI
AakarDev AI는 원활한 벡터 데이터베이스 통합을 통해 AI 애플리케이션 개발을 간소화하는 강력한 플랫폼으로, 신속한 배포와 확장성을 가능하게 합니다.
BookAI.chat
BookAI는 제목과 저자를 제공하기만 하면 AI를 사용하여 책과 대화할 수 있게 해줍니다.
skills-janitor
skills-janitor로 Claude Code 기술을 감사하고 사용량을 추적하며, 9가지 슬래시 커맨드로 자신의 능력을 비교하세요. 의존성 0.
FeelFish
FeelFish AI 소설 집필 에이전트 PC 클라이언트로 등장인물·배경을 기획하고 장을 생성·편집하며, 맥락 일관성으로 줄거리를 이어가세요.
BenchSpan
BenchSpan은 AI 에이전트 벤치마크를 병렬 실행하고 점수·실패를 실행 이력으로 정리하며, 커밋 태그로 재현 가능한 결과 비교를 돕습니다.
ChatBA
ChatBA는 채팅형 워크플로로 입력을 바탕으로 슬라이드 덱 콘텐츠를 빠르게 생성하는 생성형 AI입니다.