Fabric
Fabric is a decentralized distributed compute network that connects idle computing resources with demanding AI and machine learning workloads, offering cost-effective solutions for inference and training.
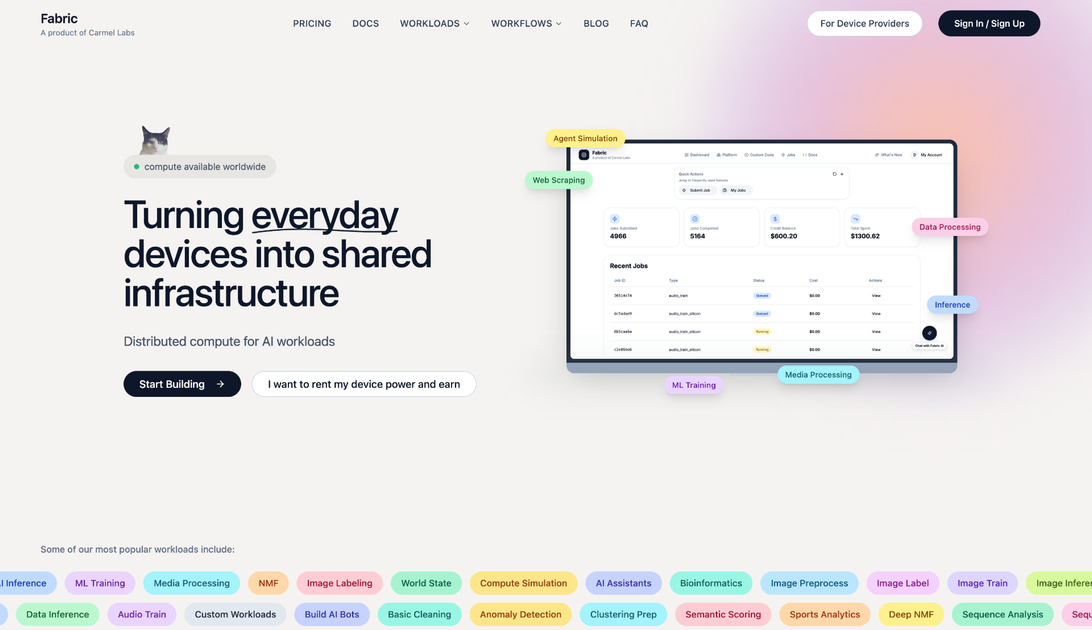
What is Fabric?
Fabric is pioneering the next generation of decentralized infrastructure by creating a global, permissionless network for distributed compute. At its core, Fabric solves the escalating cost and centralization issues associated with modern AI workloads, such as large language model (LLM) inference and complex machine learning training. By tapping into underutilized GPU and CPU capacity scattered across the globe—from data centers to individual high-performance machines—Fabric provides a scalable, resilient, and significantly more affordable alternative to traditional cloud providers.
This network acts as a marketplace where compute providers (those with idle resources) can earn passive income by serving compute requests from workload requesters (developers, researchers, and enterprises). This peer-to-peer model drastically reduces overhead, leading to inference costs that can be a fraction of standard cloud rates, democratizing access to high-performance computing for cutting-edge AI development.
Key Features
- Decentralized Compute Aggregation: Connects vast pools of idle GPU and CPU power globally, ensuring high availability and geographic distribution for workloads.
- Cost Efficiency: Offers dramatically reduced pricing for compute-intensive tasks, particularly for high-volume inference jobs, making advanced AI accessible to smaller teams and startups.
- Flexible Workload Support: Optimized for demanding AI/ML tasks, including real-time inference, model serving, and distributed training jobs.
- Permissionless Access: Open to anyone with compatible hardware to join as a provider or anyone needing compute power to join as a requester, fostering a truly open ecosystem.
- Security and Verification: Utilizes robust mechanisms to ensure the integrity and security of data and computation across the distributed nodes.
- Passive Income Generation: Compute providers can easily monetize their existing idle hardware assets by contributing to the network.
How to Use Fabric
Getting started with Fabric involves distinct pathways for those offering resources and those consuming them.
For Compute Providers (Earning Income):
- Setup Node: Install the Fabric client software on your machine, ensuring you have compatible, high-performance hardware (especially GPUs).
- Onboarding & Staking: Follow the on-screen prompts to register your hardware capacity and potentially stake tokens to signal commitment and quality.
- Accept Workloads: The system automatically matches your available capacity with incoming compute requests based on hardware specifications and geographic proximity.
- Verification & Payout: Once the job is completed and verified by the network, you receive payment directly.
For Workload Requesters (Running Jobs):
- Define Requirements: Specify your computational needs, including required GPU type (e.g., A100, H100), memory, and the nature of the task (e.g., LLM inference, fine-tuning).
- Submit Job: Submit your workload package (e.g., Docker container, model weights) to the Fabric network.
- Automated Matching: Fabric’s orchestration layer intelligently breaks down the job and distributes it across the most suitable, cost-effective nodes.
- Retrieve Results: Monitor the job progress and securely retrieve the final outputs or model responses upon completion.
Use Cases
- High-Volume LLM Inference Serving: Startups and enterprises running consumer-facing AI applications (chatbots, content generation) can deploy their models on Fabric to handle massive request volumes at a fraction of the cost of centralized cloud APIs, leading to better margins.
- AI Model Fine-Tuning and Experimentation: Researchers and ML engineers can rapidly iterate on fine-tuning large foundation models without being constrained by high hourly GPU rental rates, accelerating the pace of discovery.
- Edge AI Deployment and Data Processing: Companies needing to process large datasets or run inference closer to the data source can leverage Fabric’s distributed nature to deploy compute resources geographically where needed, reducing latency.
- Decentralized Rendering and Simulation: Beyond pure AI, Fabric can support other compute-intensive tasks like complex scientific simulations or 3D rendering farms that require burst capacity.
- Independent AI Developers: Individual developers who previously could not afford the infrastructure required to train or deploy large models can now access enterprise-grade compute power affordably.
FAQ
Q: How does Fabric ensure the security of my proprietary models and data? A: Fabric employs advanced cryptographic verification techniques and containerization (like secure Docker environments) to isolate workloads. Data is processed securely within the provider's node, and results are verified before payout, ensuring intellectual property remains protected.
Q: What kind of hardware is most valuable on the Fabric network? A: Currently, hardware equipped with modern NVIDIA GPUs (especially those with high VRAM like A10G, A100, H100) is in the highest demand for AI workloads. However, high-core-count CPUs are also valuable for certain preparatory tasks and smaller inference jobs.
Q: How is pricing determined for compute jobs? A: Pricing is dynamic, determined by supply (available provider bids) and demand (requester needs). Providers set competitive rates, and the network automatically selects the most efficient combination of resources that meet the quality and latency requirements specified by the requester.
Q: Is Fabric only for AI, or can I run general-purpose computing tasks? A: While Fabric is heavily optimized and marketed toward AI/ML workloads due to current market demand, the underlying architecture supports general-purpose distributed computing tasks that can be containerized and executed across the network.
Q: What happens if a compute provider goes offline mid-job? A: The network utilizes redundancy and fault tolerance mechanisms. If a node fails, the remaining segments of the job are automatically redistributed to other available, verified nodes in the network to ensure job completion without data loss or significant delays.
Alternatives
AakarDev AI
AakarDev AI is a powerful platform that simplifies the development of AI applications with seamless vector database integration, enabling rapid deployment and scalability.
Ably Chat
Ably Chat is a chat API and SDKs for building custom realtime chat apps, with reactions, presence, and message edit/delete.
Paperpal
Paperpal is an academic writing AI tool for research workflows—smart literature reading, English editing, rewriting, writing components, and pre-submission checks.
VForms
VForms enables the creation of interactive questionnaires overlaid directly onto YouTube videos, allowing users to collect highly contextual feedback and deep user insights.
BookAI.chat
BookAI allows you to chat with your books using AI by simply providing the title and author.
DeepMotion
DeepMotion is an AI motion capture and body-tracking platform to generate 3D animations from video (and text) in your web browser, via Animate 3D API.