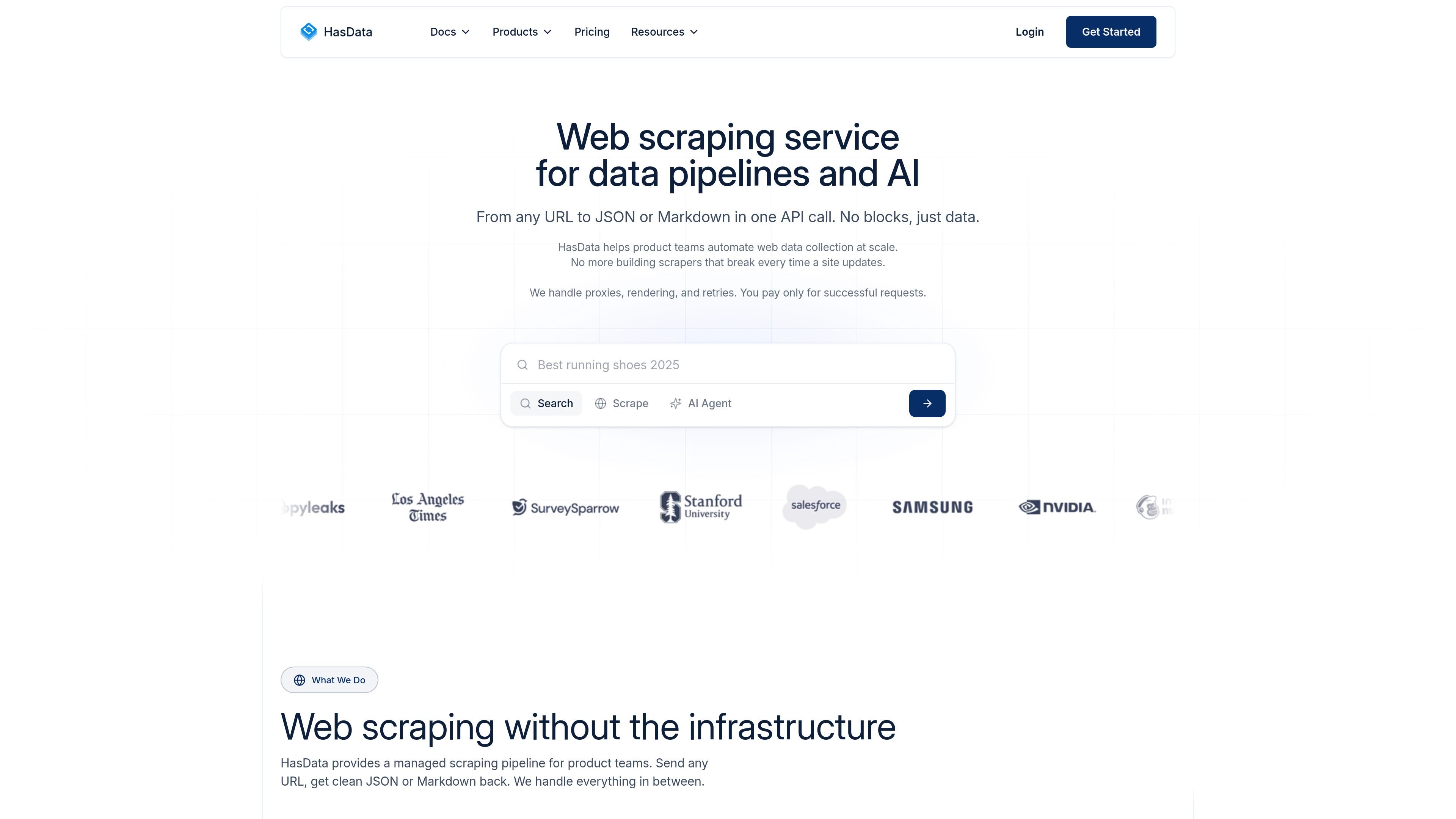
URL 到结构化输出抓取
HasData 接受一个 URL,并返回干净的结构化数据,包括 JSON 或 Markdown,因此团队可以直接将结果输入应用或 AI 工作流。
HasData 是一款网页抓取服务,用于从网站收集公开数据,并将其转换为适用于数据管道和 AI 工作流的结构化输出。其主 API 接受一个 URL,可返回 JSON、Markdown、HTML 或纯文本;而专门的抓取 API 则面向搜索、地图、产品、旅行和电商等常见来源。
该平台旨在消除抓取过程中通常涉及的大部分基础设施。网站说明它负责浏览器渲染、代理轮换、重试、CAPTCHA 处理和输出格式化,因此团队可以专注于使用数据,而不是维护抓取器。
HasData 接受一个 URL,并返回干净的结构化数据,包括 JSON 或 Markdown,因此团队可以直接将结果输入应用或 AI 工作流。
该服务支持用于 JavaScript 密集型网站的无头浏览器渲染,包括 React、Angular 和 Vue 等现代前端框架。
请求使用带轮换、地理定位和 IP 管理的托管代理系统,减少了手动配置基础设施的需要。
API 包含基于 AI 的解析和结构化提取规则,可适配不同布局的网站,而无需自定义 CSS 或 XPath 选择器。
该平台支持自动重试和 CAPTCHA 处理,因此失败请求和常见反爬障碍由服务端处理,而不是由客户端代码处理。
除 API 外,HasData 还为热门来源提供带调度功能的无代码抓取器,并可导出为 CSV、XLSX 或 JSON。
构建数据管道,将公开网站数据拉取到应用或分析系统中,而无需维护自己的抓取基础设施。
使用网页抓取 API,从依赖客户端 JavaScript 或现代前端框架的页面中提取内容。
当你需要结构化来源而不是自定义爬虫时,可针对搜索、地图、产品、旅行或电商数据运行专门端点。
使用无代码抓取器为常见网站配置定期采集任务,并将结果导出为 CSV、XLSX 或 JSON。
将公开网页中的结构化 JSON 或 Markdown 输入 AI 和 LLM 工作流,其中干净、可直接用于模型的输入很重要。
HasData 通过一次 API 调用将一个 URL 转换为结构化 JSON 或 Markdown。根据你选择的工作流,API 也可以返回原始 HTML 或纯文本。
可以。价格页面将 Scraper API 和 No-Code Scrapers 列在同一订阅模式下,常见问题摘要也说明一个订阅可同时用于两者。
来源页面说明 HasData 提供 Python 和 Node.js SDK,并支持 webhooks,这使它适合用于数据管道和自动化工作流。
来源页面显示有免费计划以及付费计划的 30 天免费试用,试用无需信用卡。网站还提供 1,000 次免费 API 调用供开始使用。
这些页面描述了通过 API 进行托管抓取,以及针对热门网站的 30 个无代码抓取器。无代码选项被描述为带有调度和导出选项的可视化界面。
Happenstance 是一款 AI 驱动的网络搜索工具,可在已连接账号中查找人脉、共同联系人和暖引荐;支持个人使用、团队共享与 API、MCP、Slack 等集成。
Geekflare Web Scraping API 是面向开发者的网页抓取 API,可提取动态页面内容并返回 Markdown、HTML、JSON 或纯文本,支持浏览器渲染、CAPTCHA 处理和代理。
Claro Research Agent 通过表格式工作流自动化人工调研,用于列表补全、公司研究、文档提取和价格监测;可独立运行,也可连接 Claro 平台实现实体感知、系统同步输出。
Spidra 是面向网页抓取的 AI API 和 Playground,帮助从难以用传统工具抓取的网站提取结构化数据,适合处理动态页面、CAPTCHA、代理轮换和登录保护内容。
Octen 为 AI 应用提供搜索基础设施,支持实时网页上下文、结构化答案与检索工具,适用于 agents、copilots 和 chatbots。支持搜索、抽取、多模态检索,以及 API、SDK、Skills、MCP、CLI 等开发接入方式。
Skayle 是一款内容与 AI 搜索可见性平台,先做主题研究再撰写,直接发布结构化内容到 CMS,并追踪品牌是否被 AI 搜索引用,适合需要一体化发布与监测的团队。