锁定的角色身份
创建一个可复用的网红身份,锁定脸部和声音,让新的生成内容始终绑定到同一个角色,而不是在不同输出之间漂移。
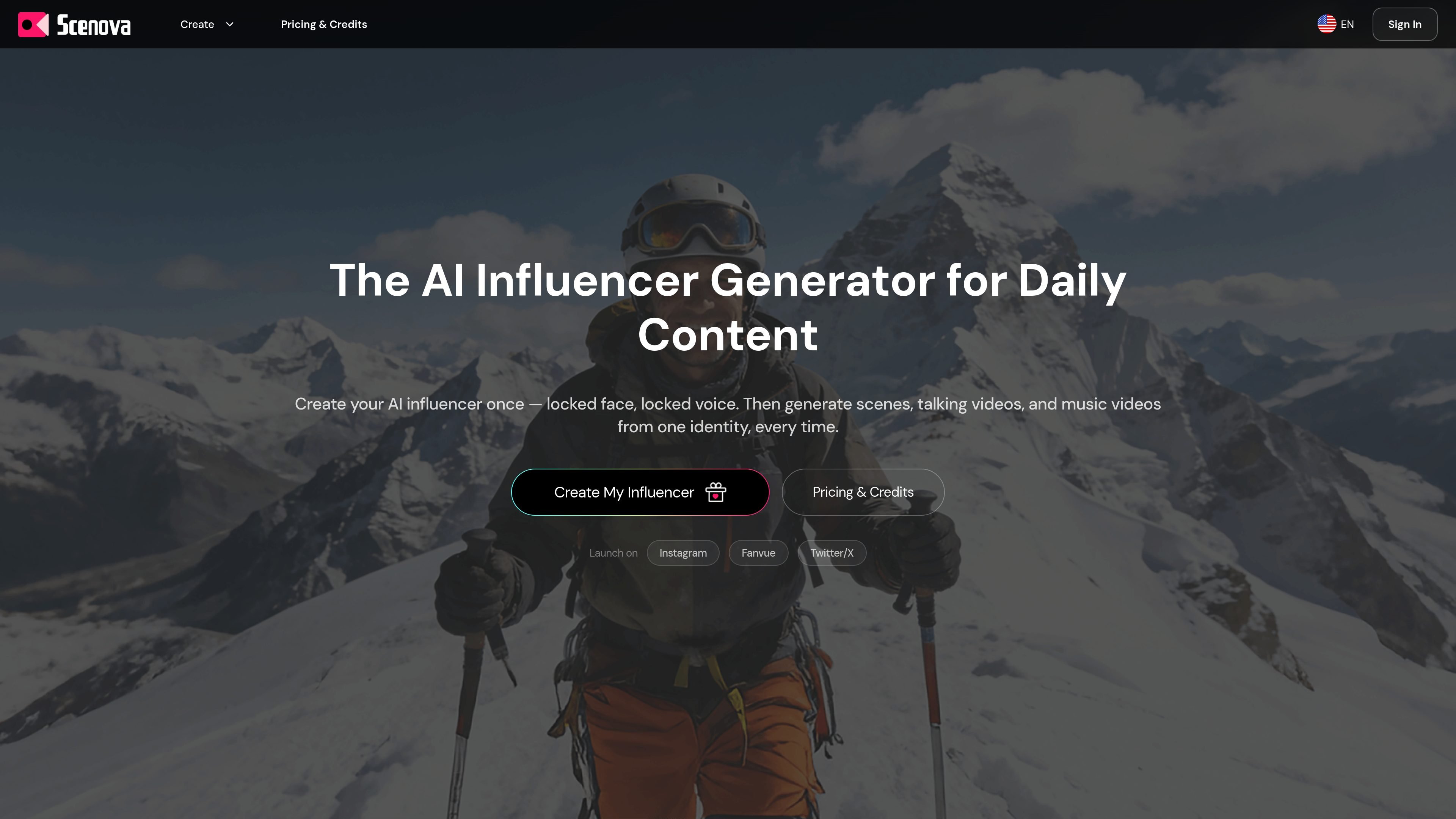
Scenova 是一款 AI 网红生成器,可创建带锁定脸部和声音的可复用虚拟角色。基于同一身份,用户无需每次重新构建角色,就能生成一致的照片、口播视频、场景和音乐视频。
该产品将网红设置、照片生成、视频生成和上线素材整合到一个工作流中。其公开定价采用订阅方案加可选积分包,并对预览、最终视频、照片、音乐视频、动作克隆和语音消息的积分规则作了明确说明。
创建一个可复用的网红身份,锁定脸部和声音,让新的生成内容始终绑定到同一个角色,而不是在不同输出之间漂移。
可通过脚本或上传音频生成口播视频,并可使用可选的情绪提示和语速控制来调整节奏与表达。
构建可复用场景并将其保存为 Master Frames,然后在未来的视频或图片生成中附加使用,以保持一致的视觉风格。
可通过提示词、上传内容或背景描述生成照片,并支持姿势和服装控制,且一次最多可批量生成 10 张图片。
从一个角色创建适合上线的素材,例如头像、横幅、简介、起步照片,以及 7 天发布日历。
先使用预览式生成检查口型同步、节奏和场景匹配,再渲染最终的 1080p 输出。
先设置一个角色身份,然后在后续帖子中重复使用,而无需每次从头重新制作脸部、声音或场景。
撰写脚本或上传旁白,先预览结果,再在节奏和口型同步合适后渲染最终的口播视频。
创建并保存场景、服装和照片变体,用于社交帖子、广告素材以及 9:16 或 1:1 等渠道专用格式。
将一个角色转化为上线素材,例如头像、横幅、简介、起步照片和新账号的发布日历。
常规生产使用订阅积分,在产量激增时再加购积分包,而无需更换基础方案。
Scenova 会将保存的脸部和声音绑定到同一个网红身份,因此场景、口播视频和音乐视频在不同生成结果之间也能保持一致。
源内容描述了脚本模式用于输入文字,以及语音模式用于上传音频。场景是可选的,可以从已保存的画面中附加,也可以不使用。
AI 照片生成器支持提示词、图片上传、姿势和服装控制,并支持一次批量生成最多 10 张照片。
定价页面显示 Scenova 采用订阅制并可选购买积分包。预览和最终生成都有公开的积分消耗,且部分高级功能仍需要有效的订阅等级。
可以。源内容说明所有套餐都包含完整的商业使用权,涵盖生成的角色、场景、视频以及相关商业用途。
VIDEOAI.ME 是一款 AI 视频生成器,可将脚本快速转为口播视频、广告、讲解视频和社媒内容,无需拍摄或传统剪辑,适合创始人、营销人员、代理商和创作者。
Topview AI 是一款基于网页的 AI 视频创作平台,适用于社媒广告、电商素材、Avatar 视频和短剧流程。支持按频道模板、提示词生成、参考上传与分镜制作。
Hedra 是面向视频、图片和音频内容规划与制作的 AI 创意平台,支持创作者和团队以 agentic 工作流生成媒体、复用品牌元素并扩展内容生产。
DANCING CATS App 可将猫咪照片变成会跳舞的猫咪短片,主打简单有趣的单一功能。页面信息简洁,适合快速了解用法,但价格、输出和功能细节未公开。
AI Song Maker 是一款基于网页的 AI 音乐生成器,可根据文本或歌词创作歌曲,并提供人声去除、音轨延长和片段替换等相关工具。
HeyGen Developers 官方 API 文档,支持制作 AI 头像视频、视频翻译、口型同步和交互式视频代理会话;适合开发者通过 API、MCP 和 CLI 工作流接入。