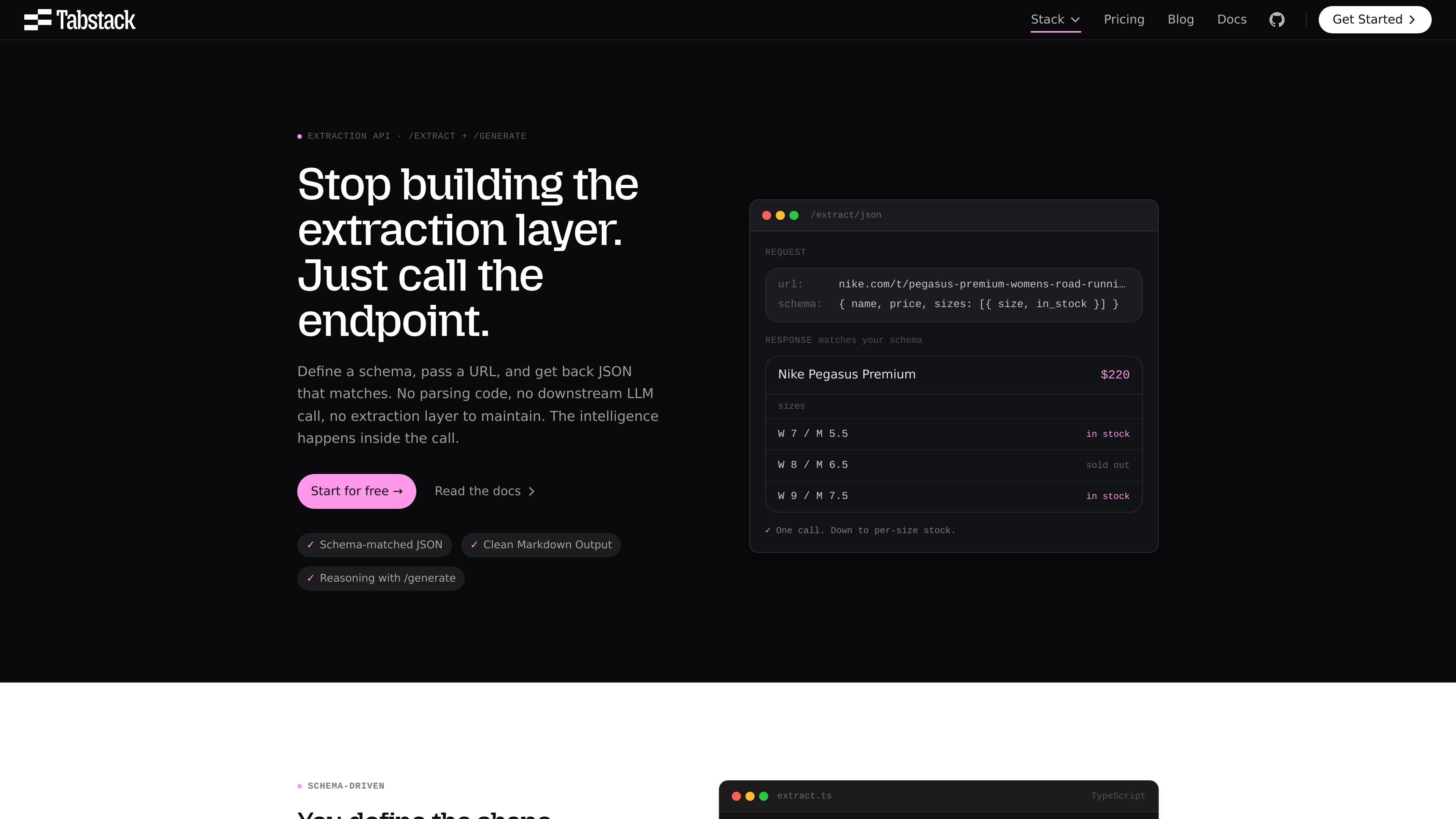
基于 schema 的提取
定义所需的 JSON 结构并发送一个 URL。Tabstack 在服务器端强制校验 schema,并返回与其匹配的输出,即使源页面发生变化也是如此。
Tabstack 的 Structured Data Extraction API 可将 URL 转为你定义的 schema 所匹配的 JSON。该产品面向需要从网页获得一致结构化输出、且无需维护自有解析逻辑、浏览器流水线或下游 LLM 编排的团队。
网站上的页面展示了两个紧密相关的工作流:`/extract/json` 用于直接按 schema 提取,`/generate/json` 用于在页面内容之上加入指令和推理。该平台还提供 Markdown 输出、带引用的研究以及浏览器自动化,但本页重点关注结构化提取用例。
定义所需的 JSON 结构并发送一个 URL。Tabstack 在服务器端强制校验 schema,并返回与其匹配的输出,即使源页面发生变化也是如此。
使用 `/extract/json` 获取固定结构数据,使用 `/extract/markdown` 获取页面文本,或在希望在源页面之上叠加指令时使用 `/generate/json`。
网站说明该提取功能适用于服务器渲染、客户端渲染以及 JavaScript 密集型页面,因此工作流并不局限于静态 HTML。
`/generate/json` 会在基于 URL 的工作流中加入指令,因此适合需要解释而非直接字段抓取的任务。
可通过 `nocache`、`effort` 和 `geo_target` 控制新鲜度与检索行为,包括重新获取最新内容和按国家/地区视图检索。
产品示例中展示了 TypeScript SDK,定价页还列出了 Python SDK、MCP 和 CLI 作为更广泛平台的访问选项。
将价格表、产品规格、库存状态或其他页面数据提取为固定 JSON 结构,供仪表盘和下游系统使用。
把域名或产品页面转为标准化的公司、产品或联系人数据,供丰富信息管道使用。
使用结构化 JSON 或 Markdown 将产品页面、文档和文章接入检索或索引管道,而无需自定义爬取代码。
当单靠页面信息不足、结果需要结构化解释时使用 `/generate/json`,例如说明某个定价页对分层策略的含义。
对于需要相关工作流的团队,同一平台还支持带引用的网页研究和对实时页面的浏览器自动化。
是。源页面展示了 TypeScript SDK 以及用于 extraction 和 research 端点的示例调用,并提供了 `/extract/json`、`/extract/markdown`、`/generate/json`、`/research` 和 `/automate` 的 API 端点文档。
结构化提取流程面向“URL + JSON schema”。Tabstack 会返回与 schema 匹配的 JSON,网站也展示了一个相关的 `/generate/json` 流程,用于基于指令的结构化输出。
主页显示该提取功能可用于服务器渲染、客户端渲染以及 JavaScript 密集型页面。它也在需要时支持干净的 Markdown 输出。
网站上公开展示了定价:有包含 10,000 credits 的免费试用、Individual 方案、包含 credits 的 Team 和 Pro 方案,以及定制定价的 Enterprise 方案。
源材料并未描述已发布的 SDK、认证方式或除页面示例之外的输出格式清单。最明确记录的输出是与 schema 匹配的 JSON、干净的 Markdown、带引用的 research 答案,以及已完成的 browser 任务。
Happenstance 是一款 AI 驱动的网络搜索工具,可在已连接账号中查找人脉、共同联系人和暖引荐;支持个人使用、团队共享与 API、MCP、Slack 等集成。
Geekflare Web Scraping API 是面向开发者的网页抓取 API,可提取动态页面内容并返回 Markdown、HTML、JSON 或纯文本,支持浏览器渲染、CAPTCHA 处理和代理。
nolainocr 是一款 AI OCR 工具,可从 PDF 发票、收据、表单、合同和银行对账单中提取结构化数据,支持导出到 Excel、Google Sheets、JSON 或 CSV,省去手动录入。
Octen 为 AI 应用提供搜索基础设施,支持实时网页上下文、结构化答案与检索工具,适用于 agents、copilots 和 chatbots。支持搜索、抽取、多模态检索,以及 API、SDK、Skills、MCP、CLI 等开发接入方式。
Skayle 是一款内容与 AI 搜索可见性平台,先做主题研究再撰写,直接发布结构化内容到 CMS,并追踪品牌是否被 AI 搜索引用,适合需要一体化发布与监测的团队。
司马阅是面向企业的AI文档智能体平台,将分散文档中的知识转化为可用于问答、检索、写作和审查的结构化能力,适合对准确性和数据安全要求较高的企业。