多種生成模式
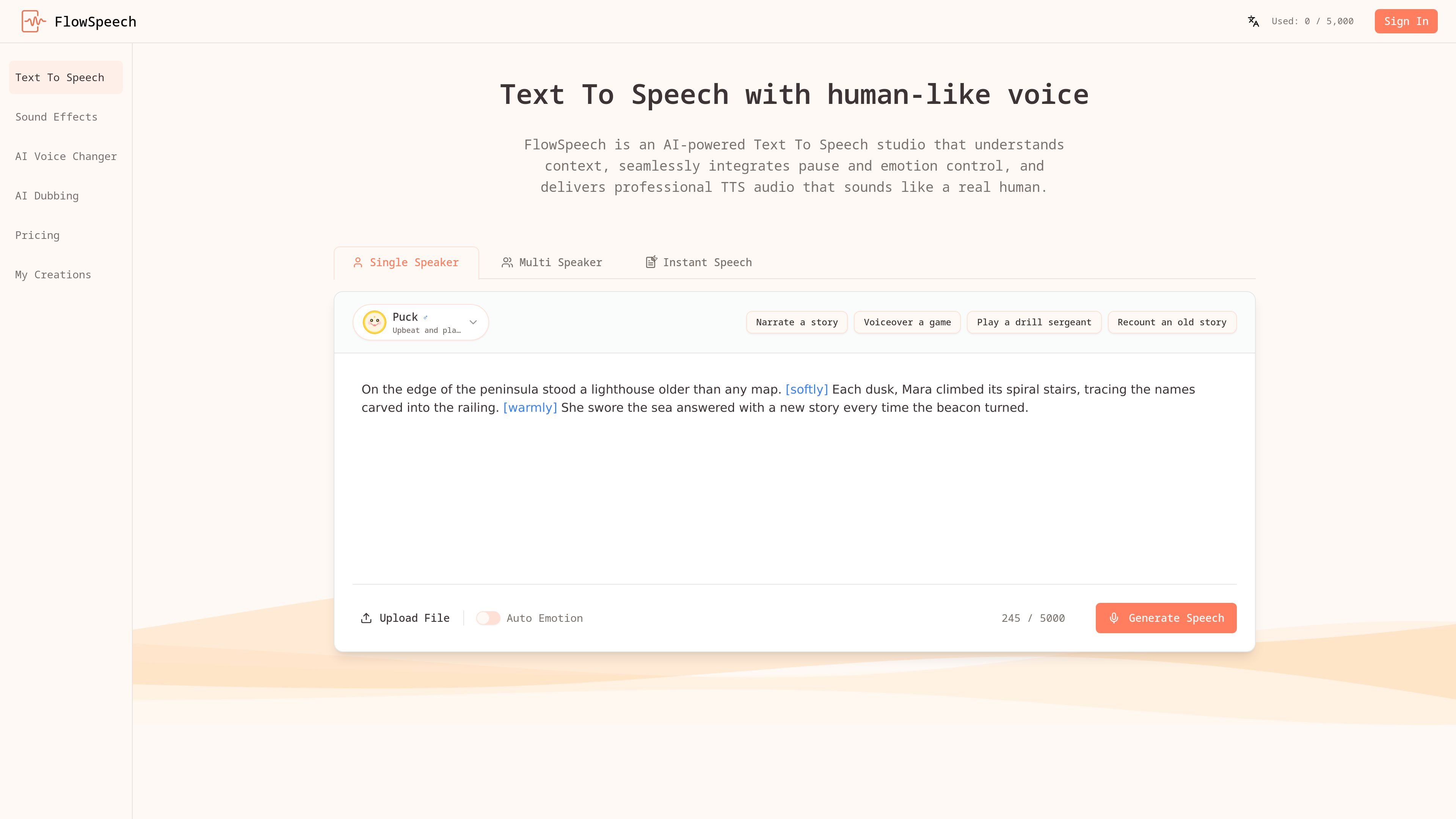
可依據你處理的是獨白、對話或快速轉換,選擇 Single Speaker、Multi Speaker 或 Instant Speech 模式來產生語音。
FlowSpeech 是一款 AI 文字轉語音工作室,可將腳本與上傳文件轉為栩栩如生的音訊。其核心設計著重於具情境感知的語音生成,因此輸出能反映情緒、節奏與細膩語氣,而不是聽起來像機械式朗讀。
產品以三種工作流程為核心:Single Speaker 用於獨白、Multi Speaker 用於對話,以及 Instant Speech 用於快速生成。使用者也可以加入方括號指令來控制停頓、情緒與口音變化,當旁白的呈現方式和內容本身同樣重要時,這項工具特別實用。
網站將 FlowSpeech 定位給創作者、行銷人員、教育工作者,以及任何製作長篇或多聲線音訊的人。它支援直接輸入文字,以及常見文件與圖片格式;首頁也將有聲書旁白、影片配音與 Podcast 風格對話列為典型應用。
可依據你處理的是獨白、對話或快速轉換,選擇 Single Speaker、Multi Speaker 或 Instant Speech 模式來產生語音。
讓系統分析腳本的語氣與節奏,使輸出能反映情境、情感與細膩差異,而不是逐行平板朗讀。
直接在腳本中插入如 [whisper]、[shout]、[strong British accent] 或 [⌛1.0s] 之類的標記,以引導情緒、口音與停頓。
上傳 PDF、DOC、DOCX、PPT、PPTX、TXT、RTF、EPUB 或圖片檔,讓 FlowSpeech 擷取文字並轉換。
可從 30 種聲音中選擇,涵蓋新聞、行銷、敘事與角色風格,並支援 70+ 種語言。
可一次渲染最長 200k 字元的長篇專案,適合章節、腳本或長篇旁白處理。
將書籍、文章與學習素材轉為長篇旁白,讓節奏與情緒表現能在長時間音訊中保持一致。
為短片、解說與產品示範製作口說音軌,並透過聲音與停頓控制讓音訊配合剪輯節奏。
透過將腳本分配給不同講者並自動指派合適聲音,建立對話、Podcast 段落與多角色場景。
將教室教材轉為課程與簡報所需的語音內容,特別適合直接匯入文件而非重新輸入腳本。
當你需要精緻結果,又不想進入 DAW 進行手動時間編輯時,可用它快速完成腳本轉音訊流程。
FlowSpeech 是一款文字轉語音工作室,可將腳本與上傳檔案轉為擬真人聲音訊,並提供具情境感知的呈現、情緒控制與停頓標記。
網站表示,FlowSpeech 支援 Single Speaker、Multi Speaker 與 Instant Speech 模式,並可透過手動情緒、口音與停頓標記,更精細地控制呈現方式。
可以。定價頁面提供免費方案,以及付費的 Basic、Pro 和 Scale 方案,因此有可免費試用的入門選項。
首頁 FAQ 有詢問是否可商業使用,但目前提供的公開頁面文字未說明授權條款,因此在將生成音訊用於商業發佈前,請先確認使用權限。
首頁 FAQ 包含資料安全相關問題,但目前收集到的文字未提供答案,因此此處無法確認隱私與保留政策細節。
Gemini 3.1 Flash TTS 是 Google 的預覽版文字轉語音模型,可生成富有表現力的 AI 語音,並細緻控制風格與呈現方式。支援 Gemini API、Google AI Studio、Vertex AI 與 Google Vids。
藍藻AI 是線上 AI 配音與語音合成工具,可將文字轉成語音,支援自助聲音克隆,適合短影音、有聲書等需要快速配音的內容場景。
Ondoku 是一款可直接在瀏覽器使用的文字轉語音工具,可將文字轉成可下載的 .mp3 語音,提供免費額度與付費方案,支援多語朗讀、圖片朗讀與按規則商用。
Typecast 是一款線上 AI 聲音生成器,可將文字轉為擬真語音,支援情感表達與多種超擬真聲音,適合在瀏覽器中快速製作配音內容。
Noiz AI 是一款 AI 文字轉語音、聲音克隆與聲音設計工具,可將文字轉為逼真語音,並在同一流程中調整情緒等聲音表現。
魔音工坊 (Moying Gongfang) 是一個智慧化的線上文字轉語音 (TTS) 平台,它能利用逼真的人類聲音和多種口音,將書面文字轉換成高品質的旁白。