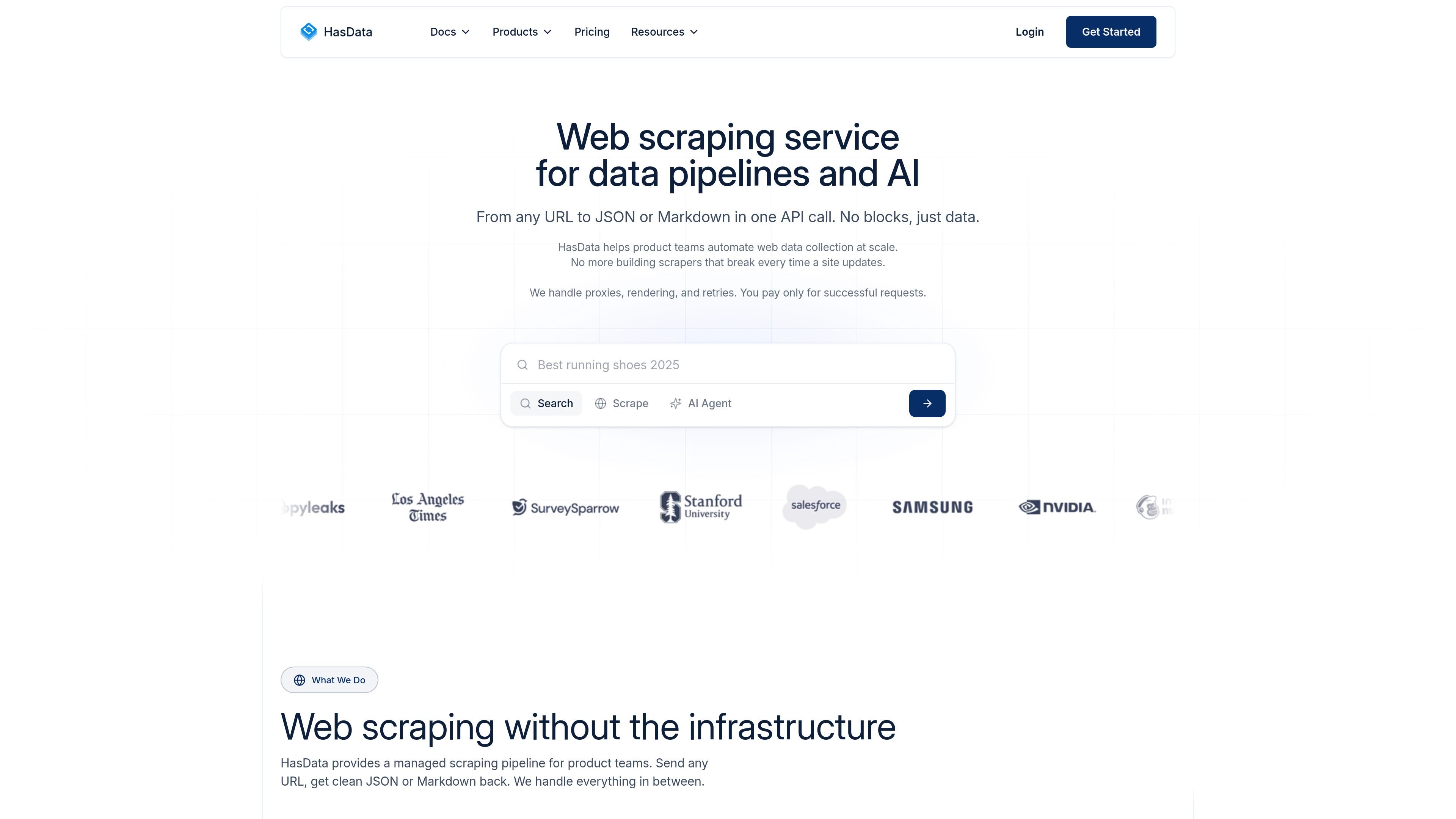
URL 轉結構化輸出爬取
HasData 接受 URL 並回傳乾淨的結構化資料,包括 JSON 或 Markdown,讓團隊可以直接將結果匯入應用程式或 AI 工作流程。
HasData 是一項網頁爬蟲服務,用於從網站收集公開資料,並將其轉換為適用於資料管線與 AI 工作流程的結構化輸出。其主要 API 接受 URL,並可回傳 JSON、Markdown、HTML 或純文字;同時也提供專門的爬蟲 API,針對搜尋、地圖、產品、旅遊與市集等常見來源。
該平台旨在移除爬蟲作業中通常需要的大量基礎架構。網站表示它會處理瀏覽器渲染、代理輪替、重試、CAPTCHA 處理與輸出格式化,讓團隊能專注於使用資料,而不是維護爬蟲。
HasData 接受 URL 並回傳乾淨的結構化資料,包括 JSON 或 Markdown,讓團隊可以直接將結果匯入應用程式或 AI 工作流程。
此服務可處理 JavaScript 密集型網站的無頭瀏覽器渲染,包括 React、Angular 和 Vue 等現代前端框架。
請求使用具備輪替、地區目標設定與 IP 管理的代管代理系統,減少手動設定基礎架構的需要。
API 包含基於 AI 的解析與結構化擷取規則,可在不使用自訂 CSS 或 XPath 選擇器的情況下,適應不同版面配置的網站。
平台支援自動重試與 CAPTCHA 處理,將失敗請求與常見反機器人障礙交由服務端處理,而非客戶端程式碼。
除了 API 之外,HasData 也為熱門來源提供無程式碼爬蟲,支援排程並可匯出為 CSV、XLSX 或 JSON。
建立管線,將公開網站資料擷取到應用程式或分析系統中,而無需維護自己的爬蟲基礎架構。
使用網頁爬蟲 API 擷取依賴用戶端 JavaScript 或現代前端框架的頁面內容。
當你需要結構化來源而非自訂爬蟲時,可針對搜尋、地圖、產品、旅遊或市集資料執行專用端點。
使用無程式碼爬蟲為常見網站設定週期性收集作業,並將結果匯出為 CSV、XLSX 或 JSON。
將公開網頁中的結構化 JSON 或 Markdown 輸入 AI 與 LLM 工作流程,當乾淨且適合模型使用的輸入很重要時特別有用。
HasData 會透過單一 API 呼叫將 URL 轉換為結構化 JSON 或 Markdown。根據你選擇的工作流程,API 也可以回傳原始 HTML 或純文字。
可以。定價頁面將 Scraper APIs 和 No-Code Scrapers 列在同一訂閱模式下,而 FAQ 片段也說明單一訂閱可同時用於兩者。
來源頁面表示 HasData 提供 Python 和 Node.js SDK,並支援 webhooks,因此很適合用於資料管線與自動化工作流程。
來源頁面顯示有免費方案,付費方案則提供 30 天免費試用,試用不需要信用卡。網站也提供 1,000 次免費 API 呼叫作為起步。
頁面說明了透過 API 的受管理爬取,以及針對熱門網站的 30 個無程式碼爬蟲。無程式碼選項被描述為具備排程與匯出功能的視覺化介面。
Happenstance 是一款 AI 網路搜尋工具,可跨已連結帳號搜尋人脈、共同聯絡人與暖身介紹,並支援個人、團隊群組、API、MCP、Slack 等整合。
Geekflare Web Scraping API 是開發者專用網頁爬取服務,可擷取動態頁面內容並輸出 Markdown、HTML、JSON 或純文字,支援瀏覽器渲染、CAPTCHA 處理與代理伺服器。
Claro Research Agent 以表格工作流程自動化人工研究,可用於名單補強、公司研究、文件擷取與價格監測;可獨立運作,或串接 Claro 平台輸出具實體感知與系統同步結果。
Spidra 是一款 AI 網頁爬取 API 與 playground,可從傳統工具難以抓取的網站擷取結構化資料。適合開發者與團隊處理動態頁面、CAPTCHA、代理輪換與登入保護內容,減少手動設定。
Octen 是一款為 AI 應用打造的搜尋基礎架構,提供即時網頁上下文、結構化回答與檢索工具,適用於 agents、copilots 與 chatbots,並支援 API、SDK、Skills、MCP、CLI。
Skayle 是內容與 AI 搜尋可見度平台,先做主題研究再撰寫,並將結構化內容發布到 CMS,追蹤品牌是否被 AI 搜尋引用。適合想用單一系統管理發布、Schema 內容與可見度監測的團隊。