本番向けRAG
Agentsetは、デモ専用のワークフローではなく、信頼性の高い回答、引用、検索品質に重点を置いた本番向けRAGのために構築されています。
Agentsetは、非公開または社内ナレッジベース上でAIチャットと検索体験を構築できるオープンソースプラットフォームです。検索パイプライン全体を自分で構築・維持せずに、本番対応のRAGを実現したい開発者向けに位置づけられています。
この製品は、信頼性の高い回答、引用、実運用の文書対応を重視しています。ホームページでは、テキスト、画像、グラフ、表を横断するマルチモーダル検索を強調しており、料金ページでは無料利用、本番アプリケーション、エンタープライズ導入向けの各ティアが示されています。
Agentsetは、デモ専用のワークフローではなく、信頼性の高い回答、引用、検索品質に重点を置いた本番向けRAGのために構築されています。
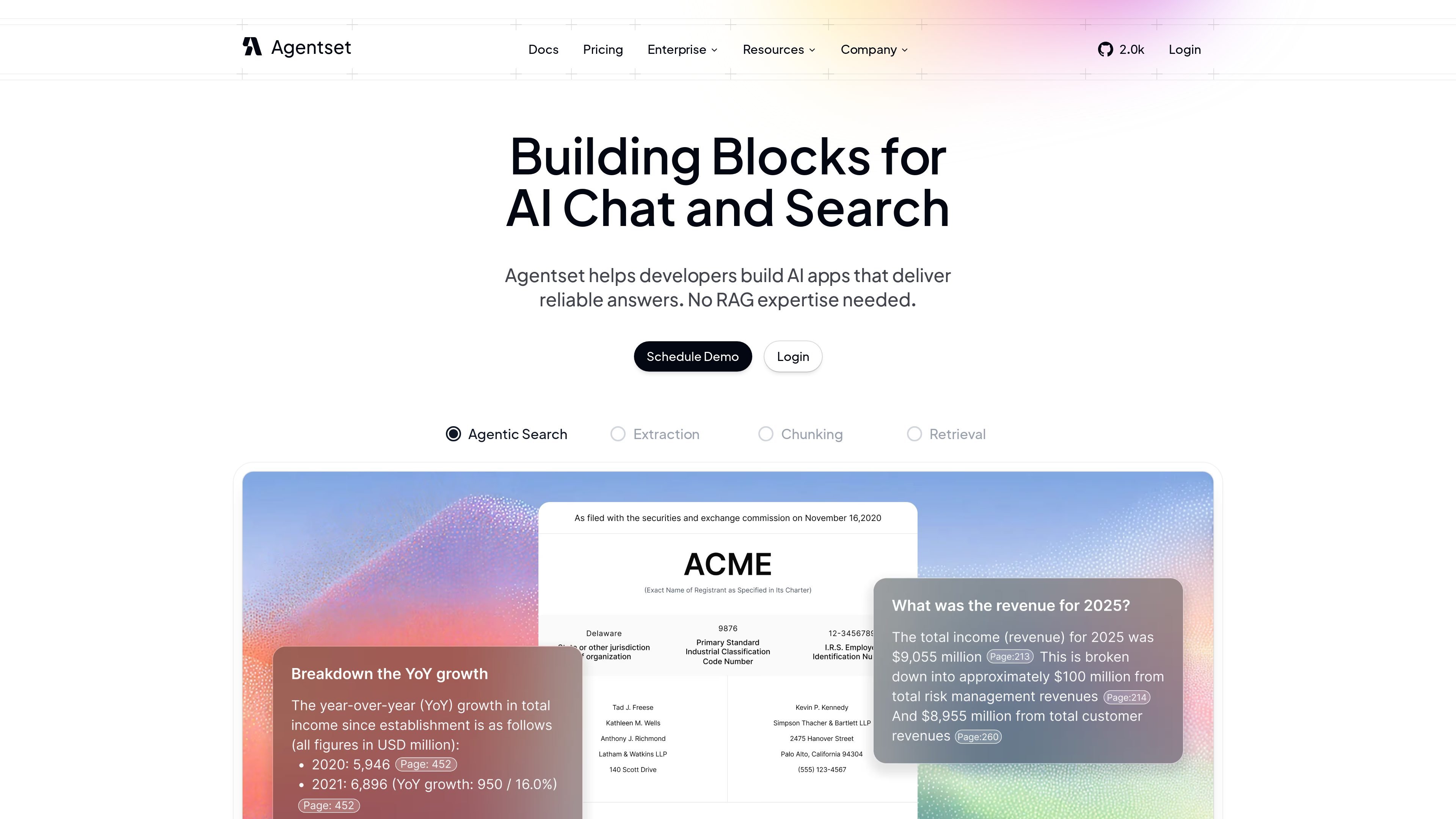
このプラットフォームは、テキストに加えて画像、グラフ、表もサポートしており、より豊富な文書セットに対して質問できます。
回答には出典引用を含めることができ、ユーザーは回答の出どころを確認し、支援資料を見直せます。
メタデータフィルタにより、対象を絞った回答が必要な場合に、コンテンツの一部に検索を限定できます。
開発者は JavaScript と Python の SDK を通じてコンテンツを取り込みでき、22 以上のファイル形式と外部アプリケーション向けの MCP サーバーに対応しています。
Agentsetは AI SDK 連携で動作でき、利用するベクターデータベース、埋め込みモデル、LLM をチームで選択できます。
社内文書やナレッジベースの上にチャットまたは検索レイヤーを構築し、一般的なチャットボット応答ではなく、引用付きで制御された検索結果が必要な場合に使います。
PDF、HTMLページ、オフィスファイル、その他対応形式を含む文書ライブラリを索引化し、フィルタリングと出典追跡付きで検索できるようにします。
Google Drive、SharePoint、Notion などの外部ソースを接続して、これらのシステムが変化してもコンテンツがナレッジベースと同期されるようにします。
MCP サーバーまたは AI SDK 連携を通じて同じナレッジベースを他のアプリケーションに公開し、より大きな製品内に検索レイヤーが必要な場合に使います。
単一目的のプロトタイプではなく、本番デプロイオプション、カスタムワークフロー、またはエンタープライズサポートを必要とするチーム向けにプラットフォームを利用します。
Agentsetは、プロダクション対応のRAGアプリケーションを構築する開発者向けのインフラ製品です。ホームページでは、製品内の検索とQ&Aのためのプラットフォームとして説明されており、料金ページには個人利用、プロダクション用途、エンタープライズ向けワークフローの各プランが示されています。
ソースには詳細なセットアップ手順は示されていませんが、JavaScript と Python の SDK、MCP サーバー、AI SDK 連携が記載されており、既存の開発スタックに組み込むことを想定していると考えられます。
Agentsetは、テキスト、HTML、PDF、オフィス系ドキュメントなど多くの一般的な形式に対応したファイルベースの取り込みをサポートしており、Google Drive、SharePoint、Notion などのサービス向けの外部データコネクタもサポートしています。
はい。料金ページには、Freeプラン、プロダクションアプリケーション向けのProプラン、カスタムワークフローとデプロイオプションを備えたEnterpriseプランがあります。また、プランはアップグレードやダウングレードが可能であるとサイトに記載されています。
ソースによると、Agentsetは回答とともに引用や出典参照を返すことができ、メタデータフィルタリング、ハイブリッド検索、再ランキング、画像・グラフ・表などのマルチモーダルコンテンツに対応しています。
AakarDev AIは、AIプロバイダーのアクセス管理、プロジェクト別設定、ログ、分析を1つのダッシュボードで管理できるチーム向けツールです。BYOKに対応し、OpenAI、Google Gemini、Anthropic、Groq、Mistral AI、Perplexity AIをサポートします。
CreateOS Sandboxは、FirecrackerマイクロVM上でコードやエージェントのワークロードを実行できる分離型コンピュート環境です。SDK、CLI、MCPで制御可能。
ByteAskは、C/C++向けのターミナル起点AIコーディングエージェント。リポジトリを編集し、コンパイラやデバッガ、サニタイザ、テストで変更を検証してから差分を表示。無料枠あり。
Codex Plugins は、再利用可能なスキル、アプリ連携、MCPサーバーを Codex app や Codex CLI で使えるワークフローにまとめます。接続サービスの作業や共有チームワークフローを拡張できます。
hobは、エージェントのセッション、ターミナル、履歴、後続作業を、既存のツールやプロバイダーに合わせて整理できる独立したコーディングエージェント向けワークスペース。ローカルでの制御を重視する開発者に最適。
Ably Chatは、カスタムのリアルタイムチャットアプリを構築できるチャットAPIプラットフォームです。ルーム単位のメッセージ、入力中表示、プレゼンス、リアクション、メッセージ更新に対応し、利用量ベースの料金も選べます。