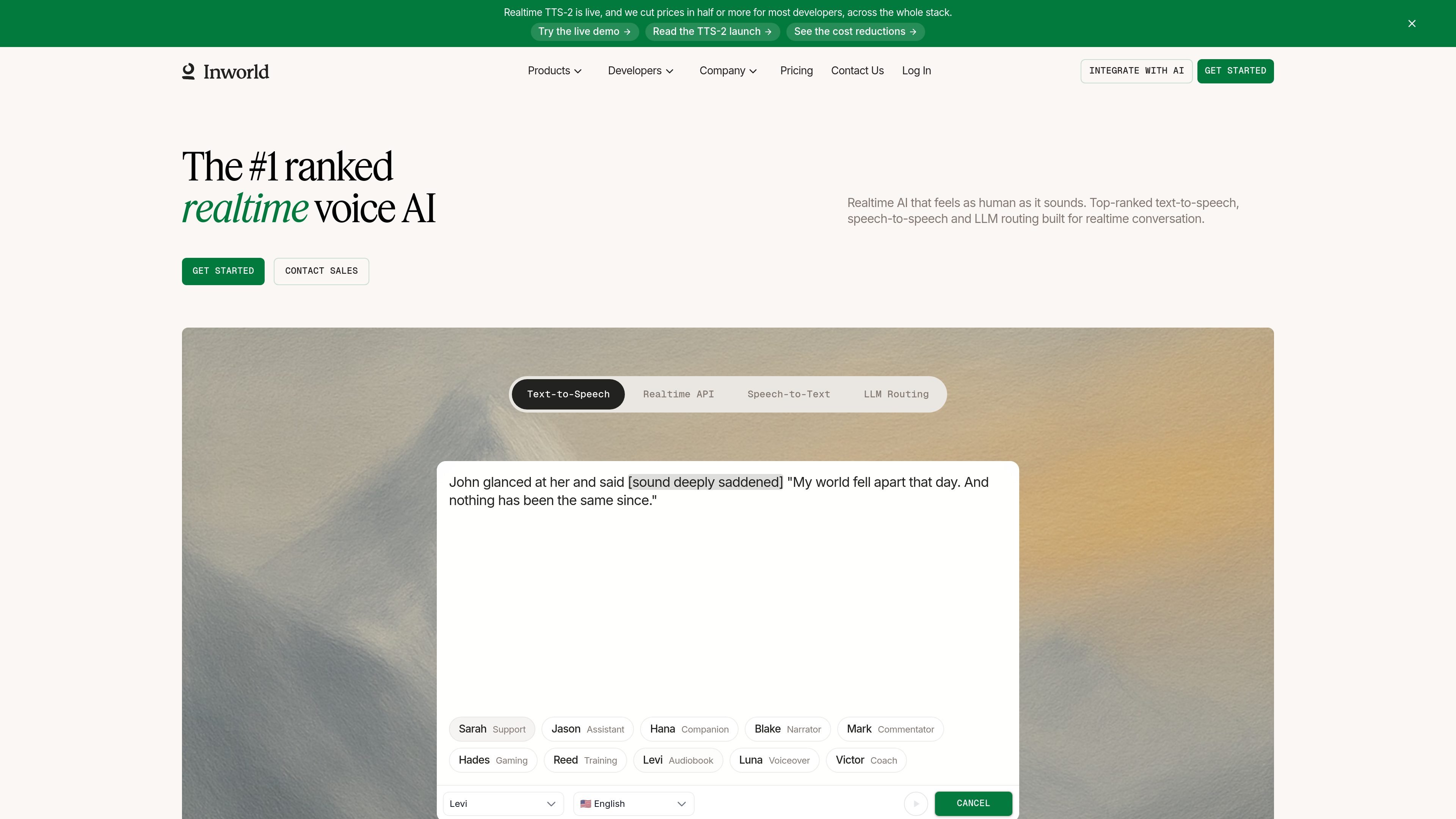
实时流式 TTS
通过流式输出实时生成音频,使语音可在完整回复结束前开始播放。网站描述该语音产品的首块延迟低于 200 毫秒。
Inworld AI 是面向开发者构建实时语音体验的语音 AI 平台。网站重点围绕文本转语音,同时提供语音转文本和 LLM 路由产品,并将平台定位于智能体、应用和其他流式语音工作流。
语音产品强调低延迟流式生成、自定义声音创建和多语言交付。源页面显示可通过少量音频样本进行即时声音克隆、基于文本的声音设计,以及一个可在生成音频分块时进行流式传输的单一 API。
定价按用量和方案层级组织,从 On-Demand 选项开始,逐步扩展到包含月度额度、更低单价、更高并发、工作区功能和企业条款的付费方案。企业买家可申请自定义价格和条款,包括定价页展示的部署和数据驻留选项。
通过流式输出实时生成音频,使语音可在完整回复结束前开始播放。网站描述该语音产品的首块延迟低于 200 毫秒。
使用 5 到 15 秒的音频创建声音,然后可在 Playground 和 API 中复用。产品页还展示了单独的声音克隆端点。
用自然语言描述口音、音色、年龄和能量,即可在没有音频样本的情况下创建声音。网站将其呈现为可用于生产的声音设计流程。
TTS-2 产品支持 100 多种语言的语音输出,并可将克隆声音本地化为母语说话方式。源内容强调了多语言交付且不会保留口音。
可使用语速、温度、发音和非语言表达等调控选项。定价信息还显示了 TTS-2 和 TTS 1.5 等模型差异,以及不同的语言覆盖范围。
基于一个统一平台构建,同时还包含 STT 和 LLM 路由。定价页列出了 API 访问、工作区共享,以及基于方案的并发和用量限制。
为助手、角色或对话应用添加流式语音,其中响应时间会影响交互体验。
通过短样本创建品牌化或角色专属声音,然后通过 API 或 Playground 在生产环境中复用这些声音。
在保持一致声音身份的同时生成多语言语音,包括面向全球受众的本地化交付。
随着使用量增长,通过基于方案的额度、工作区共享和更高并发限制来原型验证、测试并扩展语音功能。
在构建端到端语音体验时,将语音输入、语音输出和 LLM 路由组合到一个技术栈中。
Inworld 提供来自单一平台的文本转语音、语音转文本、实时语音代理和 LLM 路由。定价页还显示了免费起步方案,以及增加额度、更高限制和批量折扣的付费计划。
源内容显示,Inworld 支持流式 TTS、基于 5 到 15 秒音频的即时声音克隆,以及无需音频样本的文本式声音设计。
是的。定价页列出了公开 API、付费层级中的工作区创建与共享,以及随着方案升级而提高的并发限制。
定价页显示,Inworld 提供 On-Demand 起步方案,以及 Creator、Builder、Developer、Growth 和 Enterprise 等付费层级。Enterprise 包括自定义定价和联系销售流程。
源内容强调了具有低于 200 毫秒首块延迟的实时 TTS,但具体适配情况取决于特定模型和用例。
Talkpal 是一款 AI 语言学习 Web 和移动应用,支持口语、听力、写作和发音练习,提供 130+ 种语言的课程、角色扮演和电话式对话练习。
QuickQuill 是一款适用于 macOS 的本地语音输入与转写应用,可在设备上录制会议、转写音频、生成摘要并导出笔记,无需使用云服务。
Speech to Text Converter 是一款基于浏览器的语音转文字工具,支持实时听写和上传音频、视频文件转录。提供免费版满足短任务,Pro 版支持无限转录、AI 摘要、翻译、说话人识别和高级导出。
OpenAI API 指南,帮助开发者为实时音频、翻译、转录、语音生成和支持音频的聊天选择合适的语音架构,并匹配对应会话类型、端点与连接方式。
Gemini 3.1 Flash TTS 是 Google 的预览版文本转语音模型,可生成富有表现力的 AI 语音,并支持对风格、语速和表达方式进行细粒度控制,适用于 Gemini API、Google AI Studio、Vertex AI 和 Google Vids。
Tactiq 是一款适用于 Google Meet、Zoom 和 Microsoft Teams 的 AI 会议记录工具,可实时转写会议,并生成摘要、行动项和后续输出。基于 Chrome 扩展,支持共享与集成,助力团队协作。