スキーマ駆動の抽出
必要な JSON の形を定義して URL を送信します。Tabstack はサーバー側でスキーマを強制し、元ページが変わってもそれに一致する出力を返します。
TabstackのStructured Data Extraction APIは、URLをスキーマ準拠のJSONに変換します。推論が必要な出力向けのinstructionベースの生成フローも搭載し、パース・ブラウザ・LLMオーケストレーションを自前で持たずに構造化Webデータを取得できます。
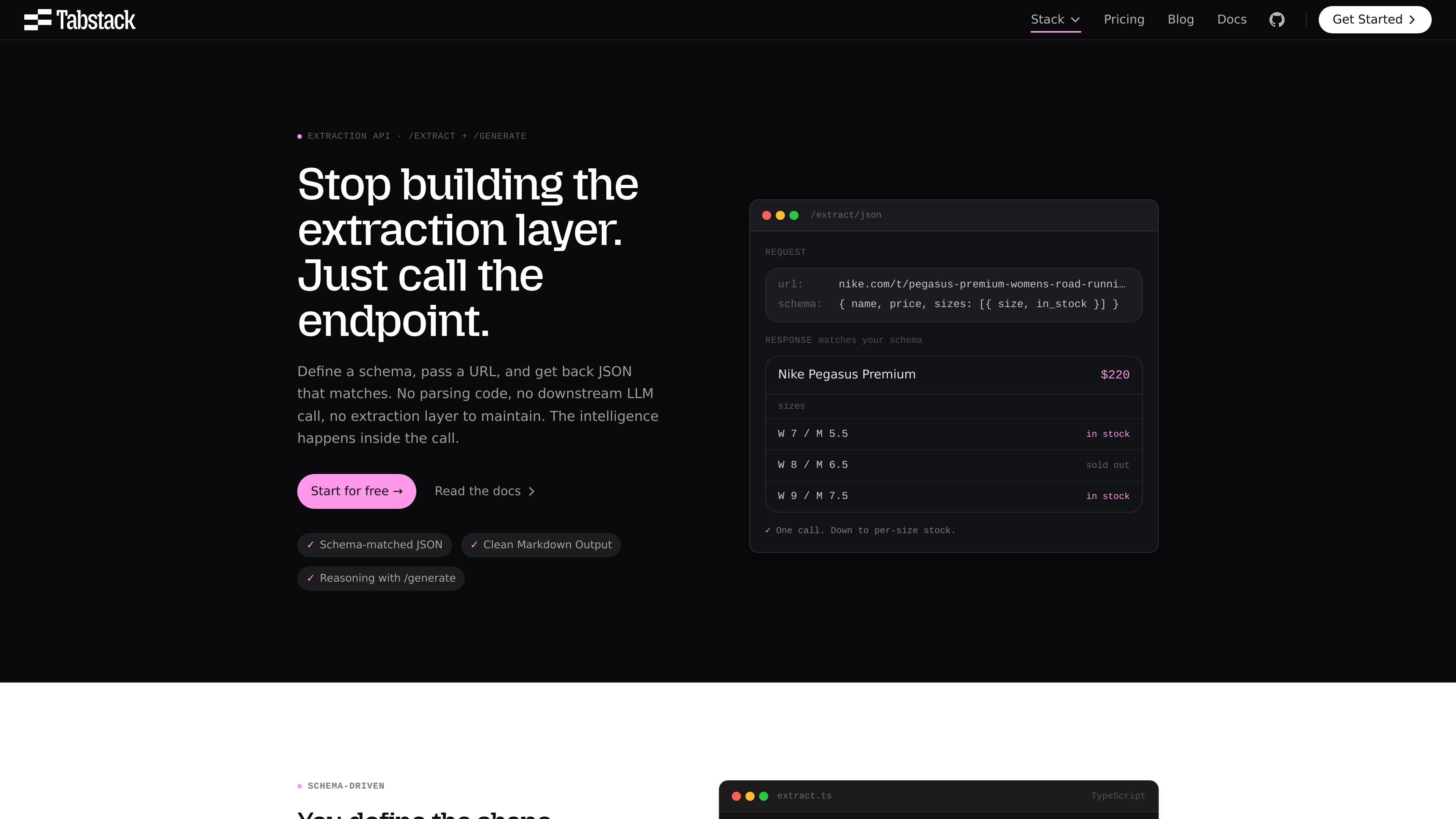
TabstackのStructured Data Extraction APIは、URLをユーザーが定義したスキーマに一致するJSONへ変換します。この製品は、自前のパースロジック、ブラウザパイプライン、下流のLLMオーケストレーションを持たずに、Webページから一貫した構造化出力を必要とするチーム向けに設計されています。
サイト上のページでは、2つの密接に関連したワークフローが示されています。`/extract/json` はスキーマに一致する直接抽出用で、`/generate/json` はページ内容の上に instruction と推論が必要なケース向けです。同じプラットフォームでは Markdown 出力、引用付き調査、ブラウザ自動化も提供されていますが、このページは構造化抽出のユースケースに焦点を当てています。
必要な JSON の形を定義して URL を送信します。Tabstack はサーバー側でスキーマを強制し、元ページが変わってもそれに一致する出力を返します。
固定形状のデータには `/extract/json`、ページ本文には `/extract/markdown`、ソースページの上に instruction を重ねたい場合は `/generate/json` を使用します。
サイトでは、抽出がサーバーサイドレンダリング、クライアントサイドレンダリング、JavaScript が多用されたページで動作すると説明されており、静的 HTML に限定されません。
`/generate/json` は URL ベースのワークフローに instruction を追加し、フィールドの単純な取得ではなく解釈が必要なタスクに役立ちます。
`nocache`、`effort`、`geo_target` を使って鮮度や取得動作を制御でき、最新取得や国別の表示にも対応します。
製品例では TypeScript SDK が示されており、価格ページではより広いプラットフォーム向けのアクセス手段として Python SDK、MCP、CLI も掲載されています。
価格表、製品仕様、在庫状態、その他のページデータを固定の JSON 形状に取り込み、ダッシュボードや下流システムで利用します。
ドメインや製品ページを正規化された会社、製品、連絡先データに変換し、エンリッチメントのパイプラインに渡します。
カスタムのスクレイピングコードの代わりに、構造化 JSON や Markdown を使って製品ページ、ドキュメント、記事を検索やインデックスのパイプラインへ取り込みます。
ページだけでは不十分で、結果に構造化された解釈が必要な場合に `/generate/json` を使います。たとえば、価格ページがセグメンテーションについて何を示唆しているかを説明するケースです。
周辺ワークフローが必要なチーム向けに、同じプラットフォームは引用付き Web 調査とライブページ上のブラウザ自動化もサポートします。
はい。ソースページには、抽出および調査エンドポイント向けの TypeScript SDK とサンプル呼び出しが示されており、`/extract/json`、`/extract/markdown`、`/generate/json`、`/research`、`/automate` の API エンドポイントもドキュメント化されています。
構造化抽出のワークフローは、URL と JSON スキーマを対象にしています。Tabstack はスキーマに一致する JSON を返し、サイトでは instruction ベースの構造化出力向けに関連する `/generate/json` フローも示されています。
ホームページには、サーバーサイドレンダリング、クライアントサイドレンダリング、JavaScript が多用されたページでの抽出が示されています。必要に応じて、きれいな Markdown 出力にも対応していると記載されています。
価格はサイト上で公開されています。10,000 クレジット付きの無料トライアル、Individual プラン、付帯クレジット付きの Team と Pro プラン、カスタム価格の Enterprise プランがあります。
ソース資料には、公開された SDK 一覧、認証方式、またはページ上の例を超える出力形式の完全な一覧は記載されていません。最も明確に文書化されている出力は、スキーマ一致の JSON、きれいな Markdown、引用付きの調査回答、完了したブラウザタスクです。
Happenstanceは、つながったアカウント全体から人脈、共通のつながり、紹介候補を見つけるAIネットワーク検索ツールです。個人利用、チーム共有、API・MCP・Slack連携に対応。
Geekflare Web Scraping APIは、動的ページからコンテンツを抽出し、Markdown、HTML、JSON、プレーンテキストで返す開発者向けWebスクレイピングAPIです。CAPTCHA対応とプロキシ対応にも対応。
nolainocrは、PDFの請求書・領収書・フォーム・契約書・銀行取引明細から構造化データを抽出するAI OCRツール。Excel、Google Sheets、JSON、CSVへ手入力なしで出力できます。
Octenは、ライブなWebコンテキスト、構造化された回答、エージェントやコパイロット、チャットボット向けの検索ツールを備えたAIアプリ向けの検索インフラです。検索、抽出、マルチモーダル検索に加え、API、SDK、Skills、MCP、CLIで利用できます。
Skayleは、執筆前にトピックを調査し、構造化コンテンツをCMSへ公開し、AI検索でのブランド引用を追跡するコンテンツとAI検索可視性プラットフォームです。
司马阅は、企業向けAI文書エージェントプラットフォーム。文書内の知識を、問答・検索・作成・審査に使える構造化能力へ変換し、精度とデータ安全性を重視する企業に最適です。