Realtime streaming TTS
Generate audio in realtime with streaming output so speech can start before the full response is finished. The site describes sub-200ms first-chunk latency for the voice product.
Inworld AI is a developer voice AI platform for realtime TTS, STT, and LLM routing with streaming voice generation, cloning, and custom plans.
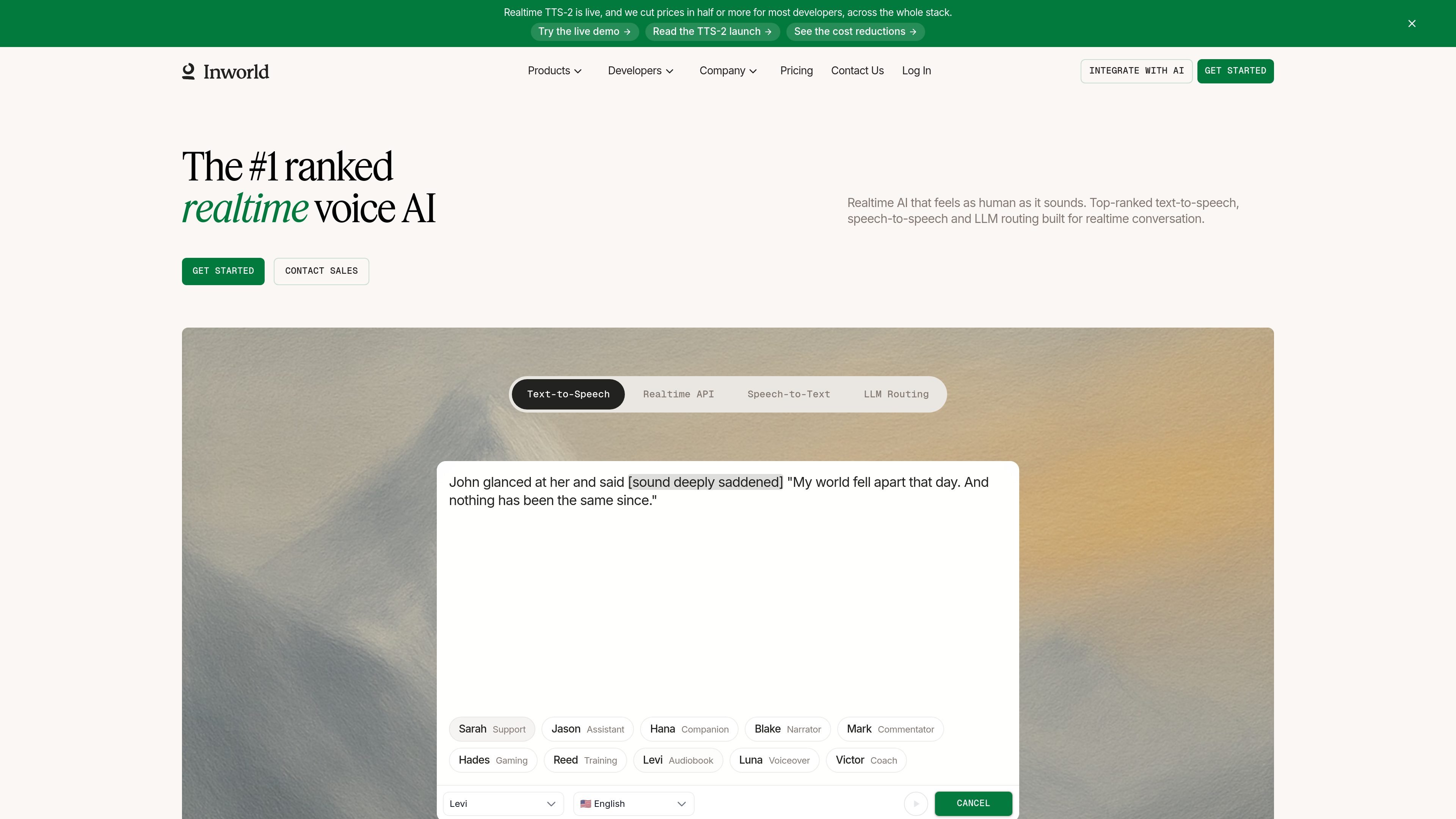
Inworld AI is a voice AI platform for developers building realtime speech experiences. The site centers on text-to-speech, with additional products for speech-to-text and LLM routing, and positions the platform for agents, apps, and other streaming voice workflows.
The voice product emphasizes low-latency streaming generation, custom voice creation, and multilingual delivery. Source pages show options for instant voice cloning from short audio samples, text-based voice design, and a single API that can stream audio chunks as they are generated.
Pricing is organized by usage and plan tier, starting with an On-Demand option and moving through paid plans that add monthly credits, lower per-unit rates, higher concurrency, workspace features, and enterprise terms. Enterprise buyers can request custom pricing and terms, including deployment and data-residency options shown on the pricing page.
Generate audio in realtime with streaming output so speech can start before the full response is finished. The site describes sub-200ms first-chunk latency for the voice product.
Create a voice from 5 to 15 seconds of audio, then reuse it across the Playground and API. The product page also shows a separate voice-cloning endpoint.
Describe accent, tone, age, and energy in natural language to create a voice without an audio sample. The site presents this as a production-ready voice design workflow.
Serve speech in more than 100 languages on the TTS-2 product and localize cloned voices to speak as native speakers. The source emphasizes multilingual delivery and no accent carryover.
Use steering controls such as speaking rate, temperature, pronunciation, and non-verbal expression. Pricing details also show model differences such as TTS-2 and TTS 1.5 with different language coverage.
Build against a single platform that also includes STT and LLM routing. The pricing page lists API access, workspace sharing, and plan-based concurrency and usage limits.
Add streamed speech to assistants, characters, or conversational apps where response time affects the feel of the interaction.
Create branded or character-specific voices from a short sample, then reuse those voices in production through the API or Playground.
Generate speech in multiple languages while keeping a consistent voice identity, including localized delivery for global audiences.
Prototype, test, and scale voice features with plan-based credits, workspace sharing, and higher concurrency limits as usage grows.
Combine speech input, speech output, and LLM routing in one stack when building end-to-end voice experiences.
Inworld provides text-to-speech, speech-to-text, realtime voice agents, and LLM routing from a single platform. The pricing page also shows a free start and paid plans that add credits, higher limits, and volume discounts.
The source shows Inworld supports streaming TTS, instant voice cloning from 5 to 15 seconds of audio, and text-based voice design without an audio sample.
Yes. The pricing page lists a public API, workspace creation and sharing on paid tiers, and higher concurrency limits as plans scale up.
The pricing page shows an On-Demand start plus paid tiers for Creator, Builder, Developer, Growth, and Enterprise. Enterprise includes custom pricing and contact-sales flow.
The source highlights realtime TTS with sub-200ms first-chunk latency, but the exact fit depends on the specific model and use case.
Talkpal is an AI language learning app for web and mobile with speaking, listening, writing, pronunciation practice, guided courses, roleplays, and 130+ languages.
QuickQuill is a local-first macOS dictation and transcription app to record meetings, summarize audio, and export notes without the cloud.
Speech to Text Converter is a browser-based transcription tool for live dictation and uploaded audio or video files. Free for short tasks, Pro offers unlimited transcription, AI summaries, translation, speaker ID, and advanced exports.
OpenAI API guide for choosing the right speech architecture for live audio, translation, transcription, speech generation, and audio-capable chat.
Gemini 3.1 Flash TTS is Google’s preview text-to-speech model for expressive AI speech with fine-grained style and delivery control across Gemini API, Google AI Studio, Vertex AI, and Google Vids.
Tactiq is an AI note taker for Google Meet, Zoom, and Microsoft Teams that transcribes meetings live into summaries, action items, and follow-up outputs.